数据库索引那些事儿,结合几个真实例子慢慢说给你听

想象一下一本厚厚的电话簿
要理解索引,最经典的例子就是一本按姓氏拼音排序的电话簿,如果你想找“张三”的电话,你不会从第一页开始一页一页地翻,因为你知道那样太慢了,你会直接翻到“Z”开头的部分,然后找到“张”,再快速找到“张三”,这本电话簿本身内容是按顺序排好的,这个“顺序”就是一种天然的索引,它让你能快速定位。
如果把电话簿里的所有名字和电话号码都打乱顺序印在一本巨大的书上,找一个人就得从头翻到尾,那效率就太可怕了,数据库里的表,在没有索引的时候,就像这本打乱顺序的电话簿,当你要找一条特定数据时(比如查找用户名为“张三”的用户),数据库就得进行所谓的“全表扫描”,把表里的数据一行一行地看过去,直到找到为止,数据量小的时候还行,一旦有上百万、上千万条数据,速度就会慢得让人无法接受。
给数据库加个“目录”:索引的原理
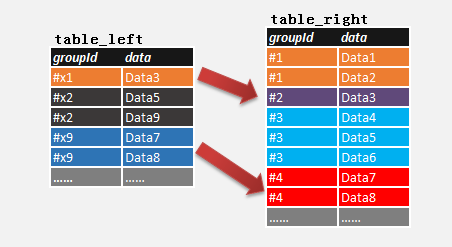
索引的作用,就是给这本“打乱的数据书”加上一个像电话簿一样有序的“目录”,这个“目录”(也就是索引)是独立于真实数据另外存储的,它只包含两样关键东西:
- 你经常用来查找的那个字段的值(用户名”)。
- 这个值对应的那条真实数据在硬盘上的“地址”(就像电话簿里“张三”所在的那一页的页码)。
这个“目录”里的条目是按照这个字段的值排好序的(比如用户名按字母顺序排),因为索引体积小且有序,数据库就可以用一种非常高效的算法(最常见的是B-Tree,你可以想象成一种快速折半查找的升级版)来快速找到你要的那个值,然后根据它附带的“地址”,直接去硬盘上把整条数据取出来。
这个过程,就像你先看有序的目录找到页码,再直接翻到那一页,比一页页翻全书快太多了。
真实例子一:电商网站的商品搜索
假设你经营一个电商网站,有一个巨大的商品表,有几千万条商品记录,其中一个核心功能就是让用户搜索商品。
- 没有索引的噩梦:如果商品名称字段没有索引,每当用户搜索“iPhone 15”,数据库就必须扫描这几千万条记录,逐行对比商品名称是不是“iPhone 15”,可能搜一次要几十秒,网站直接就卡死了。
- 加上索引的快感:你在“商品名称”这个字段上创建了一个索引,现在用户再搜“iPhone 15”,数据库不再扫描全表,而是去查询那个已经按商品名称排序好的索引,它快速定位到所有包含“iPhone 15”的索引条目,然后根据条目里的地址,精准地抓取出那几十条符合条件的商品记录,整个过程可能只要零点零几秒,用户瞬间就看到结果了。
真实例子二:朋友圈的时光机(按时间排序)
再看一个例子,微信朋友圈(或者任何社交媒体),你的朋友圈数据都存在一个巨大的“动态”表里。
- 没有索引的尴尬:当你下拉刷新,想看看最新的朋友动态时,发布时间”这个字段没有索引,数据库为了找到最新的内容,它可能得先把整个表扫描一遍,找出所有的发布时间,然后排序,最后把最新的十条给你,这显然效率极低。
- 加上索引的顺滑:如果在“发布时间”上建一个索引(通常是倒序排列,最新的在最前面),数据库要获取最新动态就非常简单了,它直接去索引的最开始部分,读取最上面的十条记录对应的数据地址,然后迅速把内容呈现给你,你感觉到的“秒刷新”,背后就有索引的巨大功劳。
索引不是万能的:优点和代价
虽然索引这么好,但它也不是随便乱建的,建索引是有代价的:
- 占用空间:索引本身需要额外的磁盘空间来存储,就像一本书,目录也会占用几页纸,数据量越大,索引也越大。
- 降低写速度(增、删、改):这是最关键的代价,因为索引需要保持和数据同步,当你新增一条商品、删除一条朋友圈或者修改一个用户名时,数据库不仅要修改原始数据表,还要更新所有相关的索引,比如你修改了用户名,数据库得先把旧用户名从索引里删除,再把新用户名插入到索引的正确位置,这就像你在一本已经印好的书里增加一页,你不仅要在书里加页,还得手动去更新目录,写的操作就会变慢。
数据库管理员的一个重要工作就是做权衡:在经常需要查询(读)的字段上创建索引,以空间和写速度的轻微代价,换取读速度的巨大提升。 对于那些很少被用来查询的字段,或者经常需要批量插入、修改的表,索引就要谨慎创建。
总结一下
简单说,数据库索引就是一个“以空间换时间”的魔法小本本,它通过给数据建立有序的“目录”,让数据库能够像查电话簿一样快速找到你想要的数据,避免了可怕的全表扫描,它非常适合用在搜索条件(WHERE子句)、排序(ORDER BY)和连接(JOIN)的字段上,但因为它会影响插入和更新的速度,并且占用额外空间,所以不能滥用,理解了这一点,你就抓住了索引的精髓。
希望这几个例子能帮你把数据库索引这事儿想得明明白白。

本文由水靖荷于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/82921.html