Redis槽道那点事儿,性能飞起来了,可伸缩性也跟着嗨翻天

Redis槽道那点事儿,说白了就是Redis为了让自己从一个单打独斗的“武林高手”,升级成一个分工明确、能打群架的“战斗军团”而想出来的一个绝妙主意,在没有槽道之前,Redis虽然速度快,但能力有上限,一台机器的内存总是有限的,数据多了它就扛不住了,这就好比一个仓库管理员,记性再好,仓库堆满了也就没办法了。
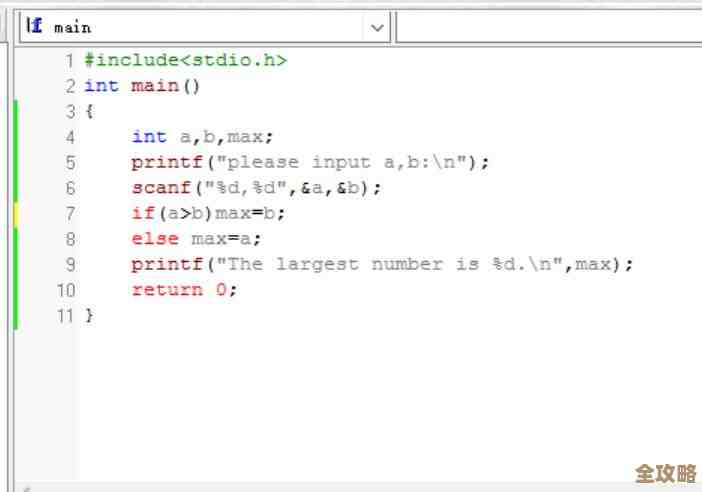
这时候,人们想到了一个朴素的办法:分而治之,弄多台Redis服务器(也就是分片),把数据分散到不同的机器上存,这不就解决单台机器容量不够的问题了吗?这个想法很好,但具体怎么“分”就成了大问题,最早的时候,客户端来决定一条数据该存到哪台机器上,用Key的哈希值对服务器数量取模,算出来是几,就存到第几台服务器上,这种方法听起来简单,但有个致命的缺点:当你想增加或减少一台服务器时(比如从3台变成4台),这个取模的底数就变了,导致绝大部分数据的位置都算错了,几乎所有的数据都需要重新搬家、重新分配,这个过程就是“重哈希”,它会让整个Redis集群在扩容或缩容期间几乎不可用,性能瞬间跌入谷底。
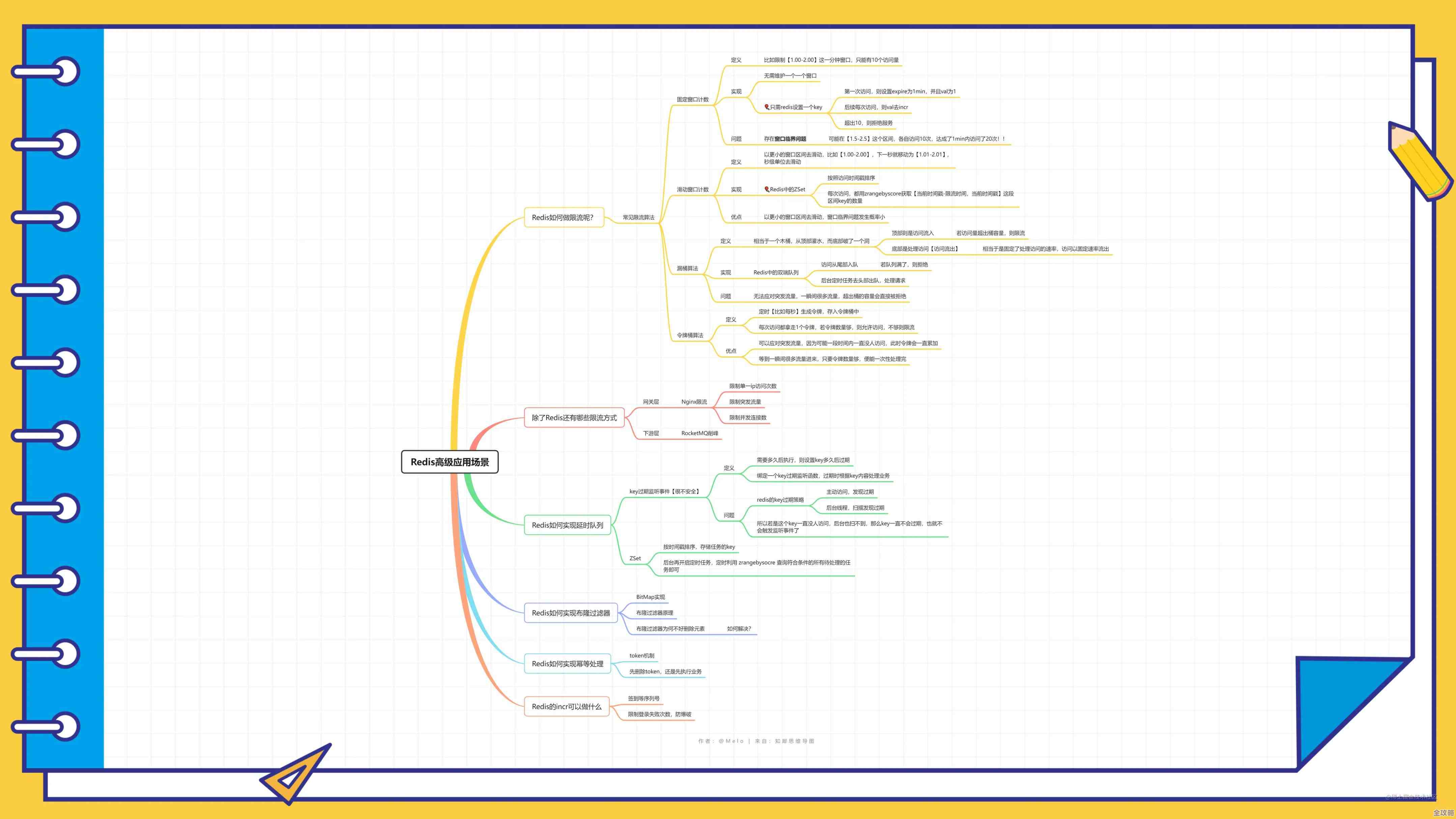
正是为了解决这个头疼的“重哈希”问题,Redis官方在3.0版本推出了自己的集群方案,而其中的核心设计就是——“槽道”(Slot),你可以把槽道想象成一个超级大的虚拟地图,这个地图被预先划分成了16384个大小均匀的区块,无论你最终有多少台Redis服务器,这个地图的区块总数是固定不变的,永远是16384个。
关键的一步来了:分配地盘,在搭建Redis集群的时候,我们会把这16384个槽道尽可能均匀地分配给集群里的每一个主节点(Master),现在有3台主节点,那么大概就是节点1管理0-5460号槽道,节点2管理5461-10922号槽道,节点3管理10923-16383号槽道,以后不管集群是扩大还是缩小,都是在这个固定的16384个槽道地图上,重新划分一下每个节点管理的范围。
一条数据具体该存到哪个槽道里呢?规则也非常简单直接:对数据的Key计算一个CRC16校验码,然后用这个校验码对16384取模,得到的结果(一个0到16383之间的数字)就是这条数据所属的槽道号,Key叫“user:1001”,计算后得到槽道号是5000,那么根据之前的分配,这个Key的数据就应该存到管理着0-5460号槽道的节点1上。
这套机制的精妙之处就在于,它把“数据应该去哪”这个复杂的问题,分解成了两个步骤: 第一步:数据到槽道的映射,这个映射规则是固定的(CRC16(key) mod 16384),只要Key不变,算出来的槽道号就永远不变。 第二步:槽道到节点的映射,这个映射是灵活的,由集群自己管理。
这样一来,当我们需要扩容,加入一个新的主节点时,集群要做的不是在所有数据上重新计算哈希,而仅仅是从现有节点管理的那些槽道中,匀出一部分(比如每个老节点拿出几百个槽道)分配给新节点,集群只会移动这些被重新分配的槽道里面的数据,其他绝大部分槽道和数据都安然不动,完全不受影响,这个过程是渐进式的,可以一边提供服务一边迁移,对性能的影响降到最低,缩容也是同样的道理。
你看,槽道就像是一个稳定的中间层,一个抽象出来的“数据地图”,它把数据的物理位置(在哪台机器)和逻辑计算(根据Key算位置)巧妙地解耦了,正是因为这个设计,Redis集群才真正实现了“可伸缩性嗨翻天”,我们可以在业务不中断的情况下,轻松地增加或减少机器,根据数据量和访问压力灵活调整集群规模,而“性能飞起来了”则得益于Redis本身的内存特性,以及槽道机制带来的高效、精准的数据定位能力,客户端可以直接连接到正确的节点进行操作,避免了不必要的转发。
Redis槽道那点事儿,核心就是用一个固定大小的虚拟分区(16384个槽),充当了数据与物理节点之间的缓冲层,它让集群的扩缩容从一场伤筋动骨、全员搬家的大手术,变成了只是局部调整管辖范围的微创手术,从而在保持高性能的同时,获得了极致的弹性伸缩能力。 基于Redis官方文档中关于Redis Cluster的数据分片模型以及槽道迁移机制的描述。)

本文由畅苗于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/82479.html