Redis到底怎么跑起来的,底层逻辑和高效运行那些事儿

Redis之所以能跑得飞快,成为互联网领域最受欢迎的缓存和内存数据库,其核心秘密在于它巧妙的设计思想和一些关键的底层机制,咱们就抛开那些难懂的专业术语,用大白话把这些事儿捋清楚。
Redis最广为人知的特点就是把所有数据都放在内存里操作,这可以说是它快的根本原因,内存的读写速度,比传统的机械硬盘快了几个数量级,甚至比固态硬盘SSD也要快得多,想象一下,你从书桌上(内存)拿一张纸,和从房间角落的档案柜(硬盘)里找一份文件,速度完全不是一个级别,Redis就是利用了这一点,让数据的读写几乎没有任何延迟,为了防止服务器断电导致内存数据丢失,Redis也提供了持久化机制,比如定期把内存数据快照保存到硬盘(RDB),或者把所有写命令记录到一个日志文件里(AOF),但这都是在后台异步完成的,尽量不影响前台的内存高速读写。
光有内存还不够,如何高效地组织和管理这些内存中的数据,才是关键,这就引出了Redis的第二个法宝:高效的数据结构,Redis不是简单地把数据扔进内存就完事了,它针对不同的使用场景,设计了多种精干的数据结构。

- 字符串(String):最简单的键值对,但也能存数字、图片甚至序列化后的对象。
- 列表(List):一个双向链表,非常适合做消息队列,可以从两头推送或弹出元素。
- 哈希(Hash):类似于编程语言里的Map,能完美地表示一个对象(比如用户信息有姓名、年龄、性别等多个字段),可以单独操作某个字段,非常节省空间。
- 集合(Set):自动去重的无序集合,可以用来存标签、共同好友等。
- 有序集合(Sorted Set):带分数的集合,能根据分数排序,排行榜功能就是它的典型应用。
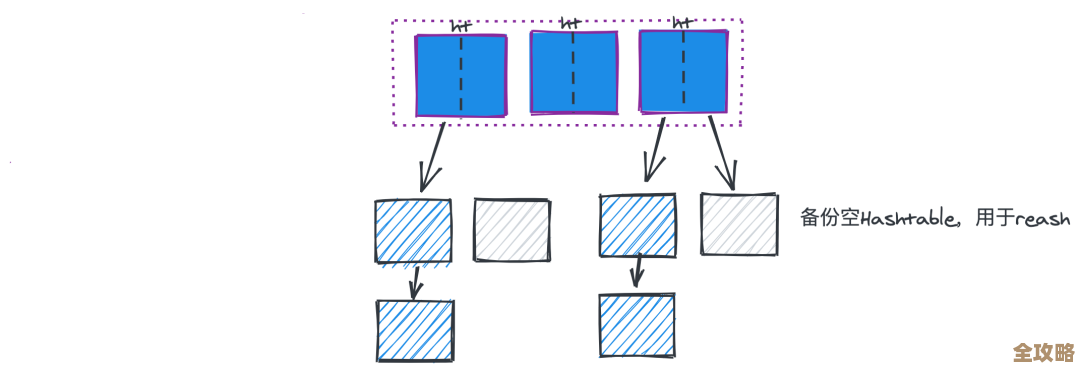
这些数据结构不是凭空想象的,而是经过了极致优化,比如它的哈希表,在数据量小时采用更紧凑的存储方式(ziplist),数据量大时才转换为标准的哈希表,以此来节约内存,这些量身定做的数据结构,使得Redis在处理各种业务逻辑时,都能找到最高效的“工具”,避免了用一把锤子去敲所有钉子的尴尬。
Redis跑得快的第三个重要原因是它的单线程架构,很多人会疑惑,现在都是多核CPU的时代了,为什么一个高性能的服务器反而用单线程?这不是自废武功吗?其实这正是Redis设计的高明之处,它的核心网络模型和键值对读写是由一个线程来完成的,这样做带来了巨大的好处:

- 避免了多线程的竞争和锁的开销,多线程虽然能利用多核,但线程之间在共享数据时需要加锁来保证安全,锁的竞争和切换本身就会消耗大量资源,单线程就完全没有这个烦恼,顺顺畅畅地干活。
- 保证了原子性,每个命令在单线程中都是按顺序执行的,不会被打断,所以每个命令都是原子操作,非常简单易懂。
那单线程怎么利用多核CPU呢?Redis的方案是“分而治之”,你可以在一台机器上启动多个Redis实例,每个实例绑定一个CPU核心,这样就能充分利用多核性能了,Redis的“单线程”主要指数据操作部分,像持久化、异步删除等一些耗时的操作,是由额外的后台线程去处理的,不会阻塞主线程。
Redis高效的另一个基石是它的I/O多路复用机制,你可以把它想象成一个超级高效的前台接待员,传统的服务器模型是一个服务员服务一个客人(连接),客人多了就得请很多服务员,成本高且切换频繁,而I/O多路复用就像一个服务员同时照看一大群客人,她不停地巡视,哪个客人的菜好了(网络数据准备好了),她就立刻端上去,这个“巡视”的过程在底层由操作系统(如epoll、kqueue)高效支持,使得Redis这个单线程的服务员能够同时处理成千上万的网络连接,而不会因为等待某个慢速的网络IO而卡住,这正是高并发能力的核心。
Redis能高效跑起来,是多个因素共同作用的结果:内存存储奠定了速度基础,精妙的数据结构是高效的武器,单线程模型避免了内耗,而I/O多路复用则赋予了它强大的并发处理能力,这几板斧下来,共同造就了Redis在数据读写方面的极致性能。 参考和融合了普遍认知的Redis核心原理,包括其基于内存的特性、丰富的数据结构、单线程Reactor模型以及I/O多路复用技术,这些知识广泛存在于技术社区如掘金、CSDN、InfoQ以及《Redis设计与实现》等经典书籍中。)
本文由凤伟才于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/82422.html