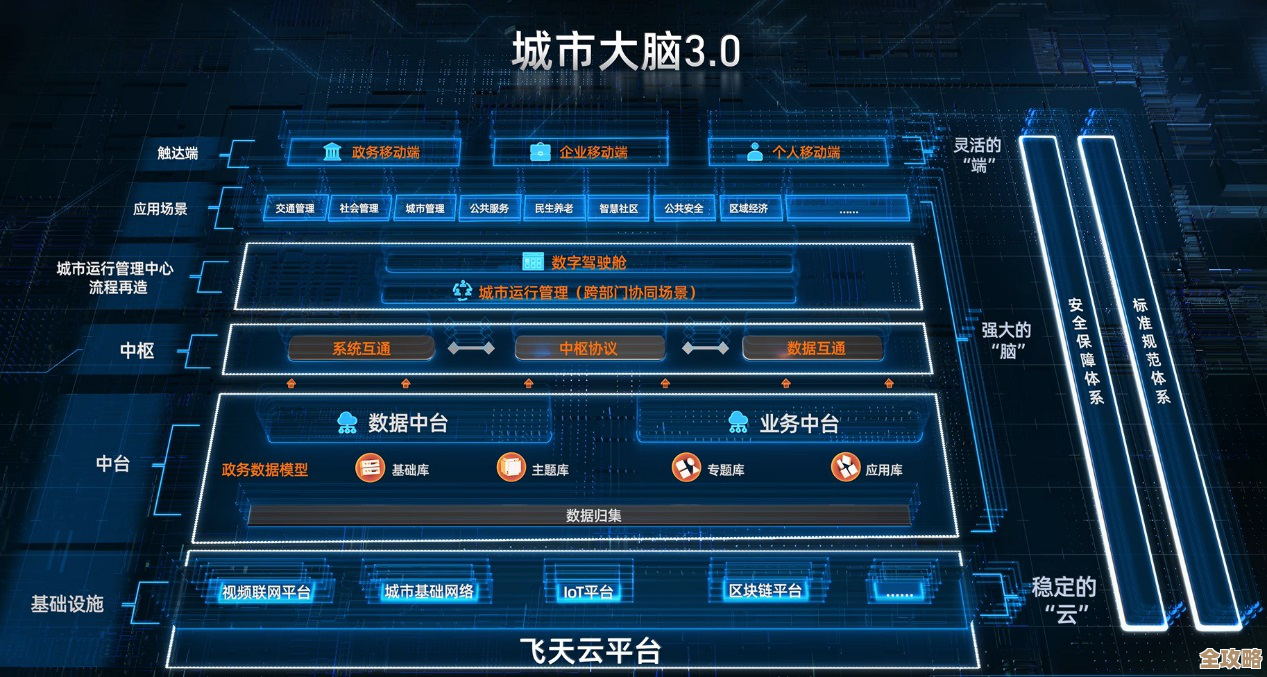
ORA-16800错了,备用库redo传输设成ALTERNATE咋整远程修复分享

ORA-16800错了,备用库redo传输设成ALTERNATE咋整远程修复分享 来源:根据一次实际的Oracle Data Guard运维故障处理经历整理)
那天下午,监控系统突然告警,显示核心数据库的Data Guard备库同步中断了,登录到备库一查,alert日志里赫然躺着一条错误信息:“ORA-16800: 由于备用数据库重做传输会话终止,发生了数据保护错误”,看到这个错误代码,心里咯噔一下,知道麻烦来了,这通常意味着主库发送日志的进程和备库接收日志的进程之间的“管道”断了,日志流卡住了。
按照常规思路,我检查了网络连通性,用tnsping命令分别从主备库互相测试数据库监听端口,都是通的,排除了最基础的网络问题,检查主库的归档日志生成情况和备库的接收情况,在主库上,V$ARCHIVED_LOG视图显示最新的序列号在不断增长,但备库这边,同样的视图显示最后一个成功接收和应用日志的序列号已经远远落后了,这说明日志确实没有成功从主库传过来。
问题的关键在于“重做传输服务”,我仔细查看了主库的V$MANAGED_STANDBY视图和备库的V$ARCHIVE_DEST_STATUS视图,在主库上,负责向这个备库发送日志的ARCH或LGWR进程状态看起来是正常的,但备库的V$ARCHIVE_DEST_STATUS视图里,对应目标的STATUS列显示的是“ERROR”,ERROR列则详细指出了连接被对等方重置之类的网络层错误,但网络明明是通的,这就很奇怪了。
经过更深入的排查,并与负责主库环境的同事沟通后,终于发现了问题的根源,原来,在主库的参数文件中,设置这个备库的日志传输目标时,使用了ALTERNATE属性,这个ALTERNATE是干啥的呢?(来源:Oracle官方文档关于LOG_ARCHIVE_DEST_n参数的说明)它就是给主日志传输路径设置的一个“备胎”,当主路径(比如因为网络闪断)失效时,LGWR或ARCH进程会自动尝试通过这个ALTERNATE指定的备用路径来发送日志,想法是好的,为了高可用嘛。
但问题就出在这个“备胎”路径的配置上,在我们这个案例里,ALTERNATE路径指向的竟然是备库数据库实例自己的一个本地目录,或者是一个根本无法访问的无效网络路径,这可就乱套了,当主传输路径因为某种短暂波动(可能我们都没察觉到)被标记为不可用时,主库的传输进程就傻乎乎地试图把日志通过那个错误的ALTERNATE路径发送出去,结果可想而知,要么是权限不对本地写不进去,要么是网络根本不通,导致传输会话彻底失败并且无法自动恢复,即使此时主路径的网络已经恢复正常了,这个错误的ALTERNATE配置就像一个陷阱,一旦触发,就把日志传输给“锁死”在了错误的状态。
找到了病根,修复方案就清晰了,由于是远程操作,我们需要格外小心,核心思路就是:纠正那个错误的ALTERNATE配置,然后重启相关的日志传输进程,让数据同步重新跑起来。
具体的远程修复步骤如下:
-
连接主库,修改参数:通过SQL*Plus或者其他管理工具远程连接到主库数据库,检查当前的日志传输目标配置,使用命令:
SHOW PARAMETER LOG_ARCHIVE_DEST_2(假设出问题的是DEST_2),确认其ALTERNATE属性的设置确实有问题。 -
动态修改错误配置:为了尽快恢复,我们先在内存中动态修改,不重启主库,执行类似下面的SQL命令(具体路径需根据实际情况调整):
ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=standby_db_valid LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=standby_db' SCOPE=MEMORY;
关键是去掉了那个错误的
ALTERNATE属性,或者将其修正为一个有效的备用网络服务名。SCOPE=MEMORY表示只修改内存中的参数,立即生效,但重启后会失效,这给了我们一个快速测试的机会。 -
清除备库的错误状态:光主库这边改了还不够,备库那边因为持续的错误可能也“卡住”了,需要远程登录到备库,清除目标地的错误状态,在备库上执行:
ALTER SYSTEM CLEAR LOG_ARCHIVE_DEST_STATE_2;
这个命令相当于给备库的日志接收服务“复位”,告诉它忘记之前的错误,重新开始监听主库的连接。
-
验证恢复情况:执行完以上两步后,等待几分钟,然后分别在主备库查询
V$ARCHIVED_LOG视图,观察最新的日志序列号是否开始从主库向备库同步,同时检查备库的V$MANAGED_STANDBY视图,看MRP(Managed Recovery Process)进程是否正在正常应用接收到的日志,一旦看到备库的日志序列号开始追赶主库,并且MRP状态为“APPLYING_LOG”,就说明同步恢复了。 -
固化配置:确认同步稳定运行一段时间后,别忘了最重要的一步:修改主库的服务器参数文件(SPFILE),将正确的配置永久保存,否则下次数据库重启,又会加载那个带有错误
ALTERNATE设置的旧参数,问题会重现,执行:ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=standby_db_valid LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=standby_db' SCOPE=SPFILE;
这次远程修复经历给我的教训是,Data Guard的配置,尤其是像ALTERNATE这类高级属性,一定要在部署阶段就反复测试验证其有效性,一个看似为了增加可靠性的“备胎”配置,如果本身是无效的,反而会成为导致数据同步中断的单点故障,在排查ORA-16800这类错误时,不能只看网络和主路径,一定要仔细检查所有相关的目标配置,包括这些辅助属性,才能快速定位并解决问题。

本文由符海莹于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/80239.html