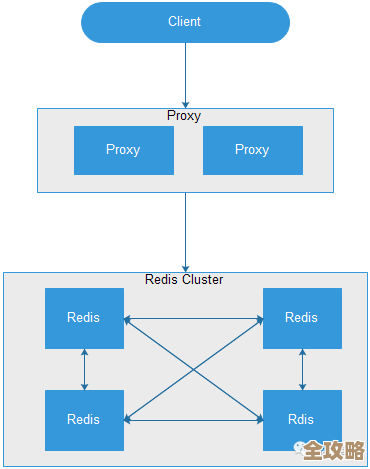
用Redis咋快速搞定海量用户活跃度统计,日活数据秒变清晰明了

关于如何使用Redis快速搞定海量用户活跃度统计,让日活等数据变得清晰明了,核心思想就是利用Redis极快的内存读写速度和丰富的数据结构,把那些频繁发生、需要快速统计的用户行为(比如登录、点击、浏览)记录下来,然后通过简单的命令就能得出结果,这比传统的关系型数据库(比如MySQL)每次都要去扫描庞大的数据表要快太多了,尤其是在用户量巨大的时候,优势非常明显。
核心思路:告别繁琐计数,拥抱内置功能
传统做法可能是这样的:用户每次活跃,就往数据库里插入一条记录,包含用户ID和时间戳,要查今天的日活,就去数据库里查询今天产生了多少条不同的用户ID记录,当数据量达到百万、千万级别时,这个查询会非常慢,数据库压力巨大。
而Redis的思路完全不同,它主要靠的是它自己内部的数据结构来“就地”完成统计,我们只需要下指令就行了,这就像是,传统方法是你有一本巨大的花名册,每来一个人你登记一次,最后再从头到尾数一遍有多少个不同的人;而Redis是给你一个智能计数器,来人它自动在对应的地方做个标记,你问它有多少人,它立刻就能告诉你数字。
具体怎么做?主要用到的几把“快枪”

根据InfoQ的一篇文章《基于Redis的海量用户实时积分排名策略》中提到的思想,虽然那篇文章主要讲积分排名,但其利用Redis有序集合(Sorted Set)进行高效统计和排序的核心思路,完全适用于用户活跃度统计,还有其他更简单的数据结构可供选择。
-
使用 Set(集合)—— 最直接的日活统计
- 干什么用:精确统计某一天(或某一特定时段)的活跃用户数,确保每个用户只计算一次。
- 怎么操作:
- 记录活跃:当用户(假设用户ID为123)在今天首次活跃时,执行一个简单的命令:
SADD activity:20231027 123,这里的activity:20231027就像是2023年10月27日这天的活跃用户花名册的钥匙。SADD命令的作用是往这个“花名册”里添加用户ID,如果用户已经存在,它不会重复添加。 - 查询日活:到了晚上想看看今天有多少活跃用户,只需要执行
SCARD activity:20231027,这个命令会立刻返回这个集合中不重复用户的数量,也就是日活用户数,这个操作的时间复杂度是O(1),意思是无论集合里有1万个用户还是1亿个用户,查询速度都是一样快。
- 记录活跃:当用户(假设用户ID为123)在今天首次活跃时,执行一个简单的命令:
- 优点:简单、精准、速度快。
- 缺点:如果需要统计很长一段时间(比如近7天)的总活跃用户数(去重后的),直接使用Set就比较麻烦,需要把7个Set合并计算,虽然Redis提供了
SUNIONSTORE这样的命令,但数据量极大时会对性能有影响。
-
使用 HyperLogLog(基数统计)—— 用极小空间搞定巨量统计

- 干什么用:当你对统计结果的绝对精度要求不是100%(有不到1%的误差),但需要以极小的内存消耗来统计海量数据的唯一用户数时,它就是神器。
- 怎么操作:
- 记录活跃:同样是用户123活跃,命令是
PFADD activity:20231027 123。PFADD是HyperLogLog的添加命令。 - 查询日活:
PFCOUNT activity:20231027,它会返回一个大概的日活数值。
- 记录活跃:同样是用户123活跃,命令是
- 优点:内存占用超级小,根据Redis官方文档(Redis Documentation)的说法,每个HyperLogLog只需要12KB内存,就能统计接近2^64个不重复元素,并且误差率很低,这对于像统计全站日活这种量级巨大、且可以接受细微误差的场景非常合适。
- 缺点:有轻微误差,不能精确到个位数,并且你无法知道具体是哪些用户活跃了,只能知道大概的数量。
-
使用 Bitmap(位图)—— 极省空间的精细画像
- 干什么用:非常适合做非常细粒度的活跃记录,比如记录用户连续签到、统计某一天哪个时间段的用户活跃情况,或者做用户标签,在《Redis实战》这本书里,Bitmap被描述为一种利用极简方式表示布尔信息的高效数据结构。
- 怎么操作:它把数据简化成0和1(比特位),我们可以把用户ID映射成一个数字偏移量。
- 记录活跃:假设用户ID是123,我们可以把他映射到第123个比特位,他今天活跃了,我们就执行
SETBIT activity:20231027 123 1,这个命令的意思是,把2023年10月27日这个“位数组”的第123位设置为1(表示活跃)。 - 查询日活:使用
BITCOUNT activity:20231027,这个命令会快速数出这一天有多少个比特位被设为了1,也就是日活数。 - 高级用法:Bitmap的强大之处在于可以进行位运算,我想知道连续两天都活跃的用户数,我可以对
activity:20231027和activity:20231026这两个Bitmap做一个BITOP AND(与)操作,生成一个新的Bitmap,这个新Bitmap中为1的位,就代表两天都活跃的用户,再对这个新Bitmap做BITCOUNT就能得到数字。
- 记录活跃:假设用户ID是123,我们可以把他映射到第123个比特位,他今天活跃了,我们就执行
- 优点:极其节省内存,如果用户ID是连续的整数,那么统计1亿用户的活跃情况,每天大约只需要12MB左右的内存(1亿比特位 ≈ 11.92MB)。
- 缺点:设计和映射需要一些技巧,如果用户ID不是连续的整数,需要先映射成一个偏移量。
如何让“日活数据秒变清晰明了”?
光有数字还不够,我们还需要趋势和洞察,结合Redis的过期(Expire)特性,我们可以轻松实现:
- 滚动统计:给每天的Key(
activity:20231027)设置一个过期时间,比如31天,这样,Redis会自动删除31天前的数据,保证我们总是保留最近30天的数据,然后我们可以很方便地计算最近7天、最近30天的活跃用户(使用Set的并集或Bitmap的位操作)。 - 实时看板:因为Redis的查询速度极快,我们可以建立一个后台管理系统,前端页面随时请求,后端直接查询Redis对应的Key(如
SCARD,PFCOUNT,BITCOUNT),数据几乎无延迟地展示在看板上,真正做到“秒变清晰明了”。
总结一下选择建议:
- 要绝对精确,且用户量不是天文数字(比如日活在百万级以内),用 Set。
- 要应对海量数据,且可以接受微小误差,用 HyperLogLog,最省心省资源。
- 要极致节省内存,并且需要做更复杂的交叉分析(如连续活跃、用户分群),用 Bitmap。
在实际项目中,这三种方法可能会根据不同的统计维度混合使用,从而以极低的成本和极高的效率,构建起一套强大的用户活跃度统计系统。
本文由符海莹于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/79837.html