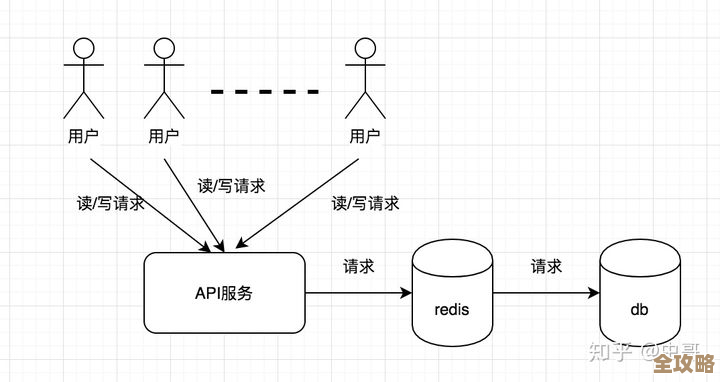
Redis搞了个6主0从的架构,实际操作和那些坑分享一下

这个事儿是听一个朋友说的,他们公司当时业务量上来了,原来的Redis架构感觉有点顶不住,就琢磨着搞个新的,也不知道是听了哪家的分享会,还是内部架构师的主意,最后决定搞一个“6主0从”的集群架构,说白了,就是弄了6个Redis主节点,每个节点都负责存储一部分数据,但是呢,一个从节点都不配。
为啥要这么干?
他们当时的想法其实挺直接的,主要有两点: 第一,为了极致的写入性能,因为所有的节点都是主节点,客户端写数据的时候,可以直接根据key算出来该写到哪个节点上,然后直接写就行了,少了主从同步那个环节,主从同步不是要把数据从主节点拷贝到从节点嘛,这个操作虽然一般是异步的,但多多少少会消耗一点主节点的资源(比如网络带宽、CPU),他们觉得,去掉从节点,就等于去掉了这个开销,写入应该能更快。 第二,省钱,这个很现实,同样是要支撑那么大的数据量和访问量,如果采用经典的一主一从或者一主多从,那需要的机器数量就得翻倍甚至更多,现在只用6台机器当主节点,就能扛住,机器成本省下来不少。
实际操作起来是啥样?

搭建过程其实还挺顺利的,用Redis Cluster模式,配置好6个主节点,让它们彼此发现组成集群,数据会自动按照槽位(slot)分片到这6个节点上,客户端用支持集群的SDK,就能正常读写了,刚开始上线那段时间,风平浪静,性能监控面板上的数字确实好看,写入延迟很低,大家觉得这步棋走对了。
坑来了:没有从节点,就等于没有备份
好景不长,第一个大坑很快就出现了,有一天,他们机房的一台物理机硬件故障了,正好就是这6个主节点中的某一个,这下可好,这个节点直接宕机,彻底失联了。
在Redis Cluster里,如果一个主节点挂了,而且它没有对应的从节点(也就是没有副本),那么整个集群就会认为这个节点负责的那部分数据槽位“失效”了,注意,不是整个集群瘫痪,而是集群会进入一个“故障”状态,具体表现就是:

- 对于原本属于那个宕机节点的数据,客户端再也无法读写了,一访问就报错,告诉你这个槽位现在没有节点服务。
- 对于其他5个正常节点上的数据,访问是完全不受影响的,该读读,该写写。
这就非常尴尬了,相当于你的数据库,有六分之一的数据突然“蒸发”了,完全不可用,虽然服务没有完全挂掉,但对于需要访问那部分数据的业务来说,就是100%的故障,这比整个集群全挂还麻烦,因为问题更隐蔽,业务方会报障说“我们部分用户登录不了”、“部分订单查不到”,你得一个个去排查是哪部分数据正好落在了那个倒霉的节点上。
恢复过程极其痛苦
因为没有从节点,所以没有任何现成的数据副本可以用来快速恢复服务,他们能做的只有:
- 赶紧找一台新机器,重新启动一个Redis实例。
- 把这个新实例作为新的主节点,加入到集群里。
- 集群会把这个新节点分配给之前宕机节点负责的那些数据槽位。
- 关键来了:这个新节点是空的! 它上面没有任何数据,这意味着,之前宕机节点上存储的那六分之一的数据,全部丢失了。
数据怎么回来?只能从源头重新灌入,比如从业务数据库里重新拉取用户信息、缓存数据等,再写入到这个新节点,这个过程非常漫长,而且依赖于业务数据库的压力和能力,在那几个小时的恢复期里,那部分数据一直是缺失状态。

另一个坑:升级和维护变得胆战心惊
经过这次教训,他们每次做运维操作都提心吊胆,想给Redis版本升级一下,正常的做法可能是先升级从节点,然后做主从切换,再升级旧的主节点,但他们没有从节点,所以升级任何一个主节点,都意味着这个节点负责的数据在升级期间会完全不可用,风险和他们遭遇的那次硬件故障一模一样,任何针对单个节点的操作,都变成了一个高风险动作。
总结一下
朋友说,这次经历让他们彻底明白了“天下没有免费的午餐”这句话,用“6主0从”这种架构,看似用更少的资源换来了更高的写入性能,但实际上是用数据的可靠性和服务的高可用性做了交换,一旦任何一个节点出问题,哪怕是很小概率的硬件故障,都必然导致部分数据丢失和服务中断,恢复起来又慢又麻烦。
他们后来老老实实地改成了“3主3从”的标准架构,虽然机器成本上去了,主从同步也有一点点性能损耗,但心里踏实啊,任何一个主节点挂了,对应的从节点能立刻顶上去,服务几乎不中断,数据也不会丢,对于绝大多数业务场景来说,后者的价值远远高于那一点点性能提升和省下来的机器钱,这种“零副本”的架构,可能只适合那种数据可以随时丢弃、丢失了也无所谓的纯缓存场景,而且还得业务方能承受部分数据不可用的风险。
本文由帖慧艳于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/79436.html