Redis查节点到底查啥,洞悉那些隐藏的秘密和玄机

说到查Redis节点,很多人第一反应就是敲个info命令看看内存、连接数,但这只是最表面的东西,就像只看一个人的穿着打扮,真正要了解他的健康状况、性格脾气,你得往深了看,今天咱们就抛开那些干巴巴的命令手册,聊聊查节点时,到底在查哪些容易被忽略的秘密和玄机。
第一层:查“生命体征”——不只是看心跳,更要看节奏
来源自Redis官方文档对INFO命令的阐述,我们常看used_memory,但高手会更关注used_memory_rss(Resident Set Size,进程实际占用的物理内存),这两者的关系藏着玄机,如果used_memory_rss远大于used_memory,说明内存碎片化严重了(mem_fragmentation_ratio比值过大),操作系统可能正在为Redis“收拾烂摊子”,这会悄悄拖慢性能,反之,如果used_memory很大但rss增长跟不上,可能触发了操作系统的Swap机制,把部分内存数据换到了硬盘上,这时性能会断崖式下跌,查内存不是看一个数字,而是看这对“兄弟”是否和谐。
再看connected_clients,数字高不一定就是问题,玄机在于blocked_clients,如果有客户端被阻塞了,说明可能有慢查询(slowlog)或者某些命令(如BLPOP)卡住了,它在提示你系统里存在“堵点”。rejected_connections这个数字如果大于零,就是个明确的警报,表示已经有过客户端因为超过maxclients限制而被拒绝连接了,系统容量可能到顶了。
第二层:查“内在活动”——洞察忙碌的真相
来源自Redis的持久化机制原理,查持久化状态是重头戏,看rdb_last_bgsave_status和aof_last_bgrewrite_status,必须是ok才行,但秘密在于,即使上次是成功的,也要关注rdb_last_bgsave_time_sec和aof_last_rewrite_time_sec,如果这个时间过长,意味着在生成快照或重写AOF文件时,Redis主进程被fork出的子进程拖累了很长时间,期间可能所有命令都会变慢,这就像工厂为了做年度盘点而暂停了部分生产线,盘点时间越长,业务受影响越大。
另一个关键是查keyspace_hits和keyspace_misses,命中率低(misses高)是缓存失效的典型症状,但玄机在于,要结合业务看模式,如果misses突然飙升,可能不只是缓存穿透(访问不存在的key),也可能是某个热点key突然失效,导致大量请求瞬间压向后端数据库,这就是常说的“缓存击穿”,查节点时发现这个比率异常,就等于抓住了系统即将雪崩的苗头。
第三层:查“关系网络”——主从与集群的暗流涌动
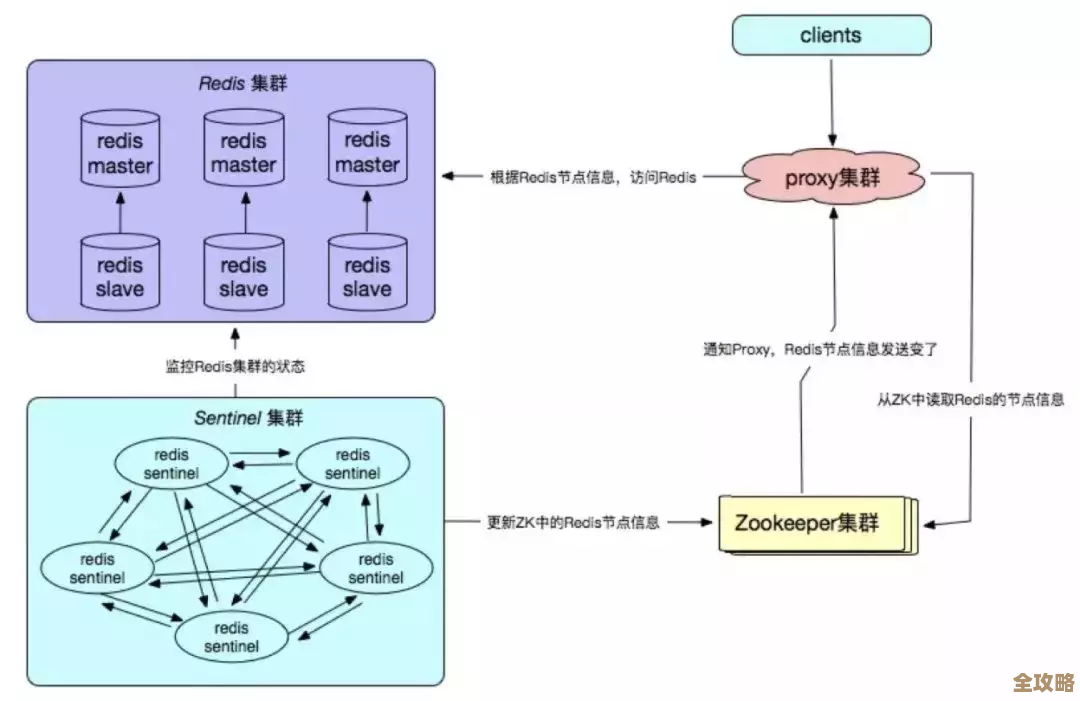
在复制(主从)架构下,来源自Redis复制协议,查master_repl_offset和slave_repl_offset(在从节点上查看)的差值至关重要,这个偏移量差值直接反映了主从之间的数据延迟,即使master_link_status显示为up,如果这个差值持续很大,说明从节点的数据是“过期”的,一旦主节点宕机,用这个从节点顶上去就会丢失一部分最新数据,这是数据一致性的一个隐藏风险点。
在Redis Cluster集群环境下,查节点不仅要看单个节点,更要看整个集群的“地图”,使用cluster nodes命令,秘密在于观察每个节点的角色(master/slave)、连接状态(connected/disconnected)以及哈希槽(slot)的分配情况,玄机藏在细节里:比如是否有某个master节点没有对应的slave(副本缺失),或者是否有哈希槽没有被任何节点服务(显示为fail),任何一个slot出现异常,都意味着整个集群有一部分数据是不可用的,节点之间的ping/pong心跳消息如果频繁超时,可能会触发不必要的故障转移,导致集群抖动。
第四层:查“历史档案”——从过去预测未来
Redis的慢查询日志(slowlog)是一个宝藏,查它不只是为了找出那些执行时间超过阈值的命令,更要分析其模式,秘密在于,偶尔出现的慢查询可能无关紧要,但如果同一类命令频繁出现在慢日志中,比如复杂的ZRANGE操作或者包含大量元素的HGETALL,这就是一个明确的性能瓶颈信号,它告诉你数据模型或使用方式可能存在问题。
通过info stats查看evicted_keys(被驱逐的key数量),如果这个数字在增长,说明内存不足已经触发了LRU/LFU等淘汰策略,这不仅是容量警报,更可能影响业务:那些你以为还在缓存里的数据,可能已经被悄悄删掉了,导致缓存命中率进一步降低。
查Redis节点,远不是运行一两个命令看看绿色OK那么简单,它更像是一次全面的“体检”,你要从静态的数字中看出动态的趋势,从单个节点的状态推演出整个系统的健康状况,关注内存碎片、持久化开销、主从延迟、集群槽位、慢查询模式、键淘汰情况这些深层指标,才能洞悉那些隐藏在表象之下的秘密和玄机,真正做到防患于未然,保证Redis这颗“心脏”强劲而稳定地跳动。

本文由符海莹于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/76000.html