MySQL里大表里那些重复字段怎么快速找出来和查查询方法分享

在网上很多技术论坛,比如CSDN、博客园或者知乎上,经常能看到有程序员问怎么处理MySQL大表中重复数据的问题,这个问题确实很常见,特别是当数据来自不同的录入渠道或者系统早期没有做好唯一性约束的时候,下面就把这些常见的方法分享一下,主要是基于SQL查询的方式。
第一部分:理解什么是“重复”
在开始查之前,最关键的是先定义清楚什么样的记录算“重复”,通常有两种情况:
- 完全重复:两条或多条记录的所有字段的值都一模一样,这种情况相对少见,一般是由于数据导入错误等原因造成的。
- 业务逻辑重复:这是更常见的情况,指的是那些不是所有字段都相同,但根据业务规则,某些关键字段的组合不能重复的记录,在一个用户表里,“身份证号”重复算重复;在一个订单明细表里,“订单号”和“产品编号”两个字段 together 重复才算重复。
第二部分:查找重复记录的查询方法
这里主要介绍几种实用的SQL查询写法,你会看到很多技术文章都在用类似的例子。
使用 GROUP BY 和 HAVING 子句(最常用)

这是最经典、最直接的方法,思路是先按照你认为可能重复的字段进行分组,然后统计每组内的记录数量,最后筛选出记录数大于1的分组。
-
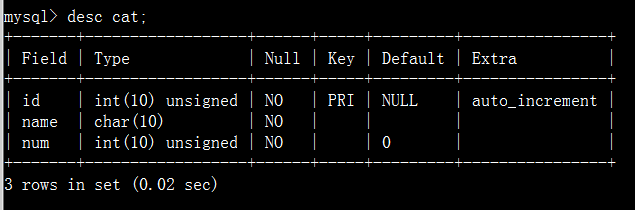
查询单一字段重复: 假设我们有一张很大的
users表,我们怀疑email字段有重复值,可以这样写:SELECT email, COUNT(*) as count FROM users GROUP BY email HAVING COUNT(*) > 1;
这个查询会列出所有重复的邮箱地址,以及它们各自重复的次数,这是来自W3Schools等SQL学习网站最基础的例子。
-
查询多个字段组合重复: 假设在
sales_records表中,我们认为“销售员ID”(seller_id)和“销售日期”(sale_date)相同的一条记录算重复,查询语句如下:SELECT seller_id, sale_date, COUNT(*) as count FROM sales_records GROUP BY seller_id, sale_date HAVING COUNT(*) > 1;
这个方法能非常清晰地告诉你,哪个销售员在哪一天重复录入了多少条记录。

使用窗口函数(适用于较新版本的MySQL)
如果你的MySQL版本是8.0或以上,窗口函数会是一个更强大的工具,它在一些性能要求高的场景下被推荐,比如来自Percona官网的技术博客就讨论过相关优化。
窗口函数的好处是,它不仅能找出哪些记录重复,还能直接标识出每一行记录,方便后续处理,常用ROW_NUMBER()函数。
还是查找users表中email的重复记录:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) as row_num
FROM users
) AS temp_table
WHERE row_num > 1;
这个查询的解释是:

PARTITION BY email:表示按照email字段进行分区,相同邮箱的记录会被分到同一个组里。ORDER BY id:在每个分区内,按照id(或其他字段)排序,给每条记录一个顺序。ROW_NUMBER():为分区内的每一行生成一个唯一的序号,从1开始。- 最外层的查询
WHERE row_num > 1,就会把每个重复分组中,除了第一条(row_num=1)之外的所有记录都找出来,这些就是你要找的重复记录。
使用自连接(Self Join)
这是一种比较老派的方法,虽然逻辑上可行,但在大表上性能可能很差,因为它是笛卡尔积的一种形式,在这里提一下是为了知识的全面性,但在实际处理大表时不太推荐。
SELECT a.* FROM users a, users b WHERE a.email = b.email AND a.id < b.id;
这个查询的意思是,将表自己连接起来,找出邮箱相同但ID不同的记录(a.id < b.id是为了避免同一行自己匹配自己,也避免重复输出),当数据量巨大时,这个查询可能会跑很久甚至拖垮数据库。
第三部分:处理大表时的注意事项和优化建议
直接对一个几千万行的大表运行这些查询,尤其是那些需要全表扫描的(比如GROUP BY),可能会产生大量磁盘I/O和CPU计算,影响数据库性能,所以需要一些技巧:
- 缩小查询范围:尽量不要一次性查全表,如果可能,加上时间范围(
WHERE create_time > ‘2023-01-01’)或者其他能有效过滤大量数据的条件。 - 在分组字段上建立索引:这是最重要的优化手段,如果你经常需要按
email查重,那么给email字段加上索引会极大加快GROUP BY email的速度,对于多字段组合重复,建立联合索引(例如INDEX(seller_id, sale_date))也会有很大帮助,很多数据库优化文章,比如MySQL官方手册,都强调索引的重要性。 - 分批处理:如果表实在太大,可以写脚本分批处理,比如每次按ID范围或时间范围取一部分数据来检查重复,最后合并结果。
- 在从库或测试环境操作:如果业务允许,尽量在数据库的从库(读库)上执行这些分析性的查询,避免影响主库的正常写入和读取。
- 使用EXPLAIN分析查询:在运行正式查询前,在语句前加上
EXPLAIN关键字,可以查看MySQL的执行计划,看看它是否使用了索引,有没有在全表扫描,从而帮你判断查询的效率。
总结一下
查找MySQL大表中的重复字段,核心方法是使用GROUP BY ... HAVING COUNT(*) > 1,对于MySQL 8.0+的用户,可以优先考虑使用ROW_NUMBER()窗口函数,功能更灵活,最关键的是,一定要结合索引和查询条件优化,避免对生产环境造成压力,找到重复数据后,删除或合并就是另一个话题了,通常需要根据业务逻辑谨慎处理,这些方法都是在实践中总结出来的,希望能直接帮到你。
本文由凤伟才于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/75989.html