Redis到底适合存啥数据,哪些用它才不浪费资源呢

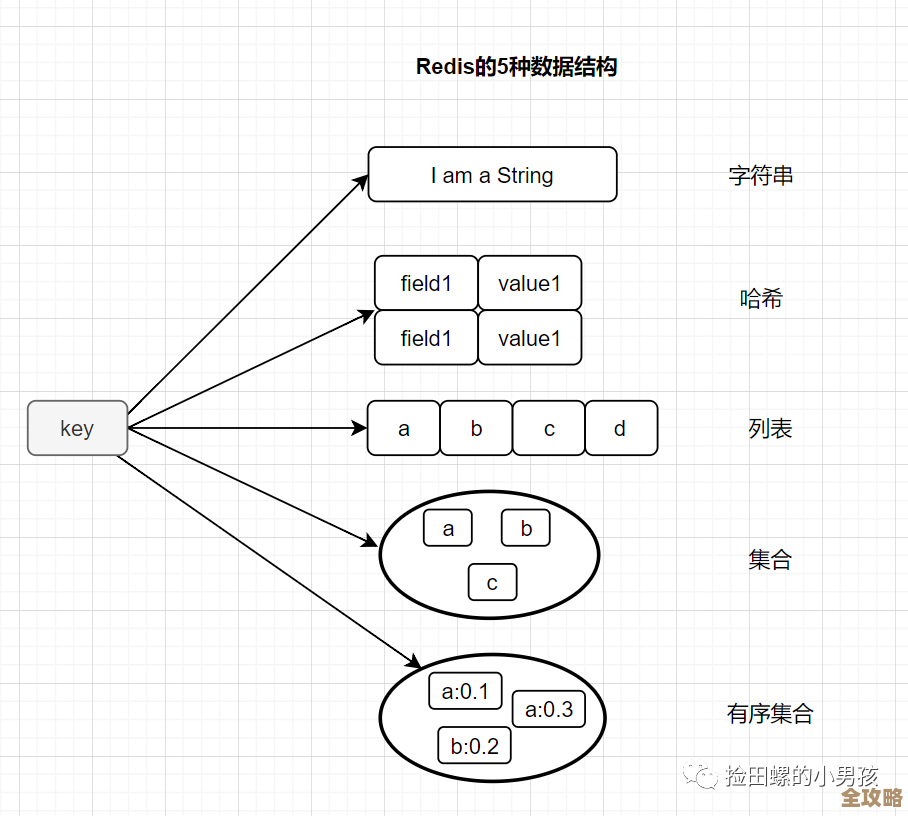
关于Redis到底适合存储什么数据,以及如何用它才不浪费资源,我们可以从Redis的设计初衷和核心特性来理解,Redis的作者Salvatore Sanfilippo(别名antirez)曾多次在博客和访谈中阐述过Redis的定位,他将其描述为一个“数据结构服务器”,其核心价值在于提供对复杂数据结构的原子性操作和极高的读写速度(来源:antirez博客“Redis宣言”),这意味着,Redis的优势不在于存储海量数据,而在于快速处理那些结构多变、访问频繁的“热”数据。
最适合使用Redis的数据类型(用它才不浪费)
-
缓存(Cache):这是Redis最经典、最普遍的用途,也是其设计的主要目标之一。 当你的应用(如网站、APP)的后端数据库(如MySQL)压力过大时,可以将频繁查询但又不经常变动的数据放在Redis里,比如用户的个人资料、商品的热门信息、文章的详情页等,用户请求时,先查Redis,如果命中就直接返回,极大地减轻后端数据库的负担,提升响应速度,这种场景下,即使Redis重启导致数据丢失,也可以从数据库重新加载,风险可控。
-
会话(Session)存储:在分布式或集群部署的Web应用中,用户的登录状态(Session)需要存储在一个所有服务器节点都能访问到的地方。 如果存在单台服务器的内存里,用户下次请求被分配到另一台服务器就会显示未登录,Redis的快速读写和持久化选项使其成为理想的分布式Session存储方案,相比传统的数据库存储Session,Redis的性能要高出几个数量级。
-
频繁更新的计数器: Redis提供了对数字类型的原子性递增(INCR)和递减(DECR)操作,这对于需要高并发计数的场景非常合适,
- 社交媒体的点赞数、阅读量、粉丝数:每一次点赞都是一个高并发的写操作,用Redis可以确保计数准确且快速。
- 限流器:限制一个IP地址或用户在一分钟内访问API的次数,通过设置过期时间,可以轻松实现滑动时间窗口的限流。
- 秒杀商品的库存计数:在高并发抢购中,库存的扣减需要绝对的原子性,Redis可以避免超卖问题。
-
实时排行榜/排行榜类数据: Redis内置的有序集合(Sorted Set)数据类型是天生的排行榜利器,它可以轻松地根据分数(Score)对成员进行排序,并支持范围查询,比如游戏里的玩家积分榜、直播间的送礼贡献榜、新闻的热搜榜等,这些数据变化非常频繁,且对实时性要求极高,用传统数据库排序会消耗大量资源,而Redis处理起来则游刃有余。
-
消息队列(轻量级): 虽然不如专业的消息队列(如Kafka、RabbitMQ)功能全面,但Redis的列表(List)和发布订阅(Pub/Sub)功能可以实现简单的消息队列功能,适用于对消息可靠性要求不是极端苛刻、但追求极高速度的场景,比如系统内部的任务派发、实时通知等。
-
需要快速判断存在的场景: 利用Redis的集合(Set)或布隆过滤器(Bloom Filter,可通过Redis模块实现),可以快速判断某个元素是否存在一个巨大的集合中,且占用空间极小,典型的应用是防止缓存穿透(查询一个根本不存在的数据,避免频繁击穿数据库)和垃圾邮件过滤(判断一个邮件地址是否在黑名单中)。
哪些情况使用Redis可能浪费资源(甚至不合适)
-
作为主要持久化数据库(Primary Database): Redis的持久化(RDB快照和AOF日志)是为了保证数据可恢复性,但其设计核心依然是内存操作,如果你的数据量巨大(比如几个TB),远超服务器内存容量,或者数据本身价值很高,不允许有任何丢失风险(即使配置了持久化,在极端情况下仍有微小概率丢失数据),那么应该使用MySQL、PostgreSQL等关系型数据库或HBase等分布式存储作为主数据库。
-
存储冷数据或大体积二进制数据: Redis的数据全部放在内存中,内存成本很高,如果你要存储的是几百兆的视频文件、大量的历史日志记录等很少被访问的“冷数据”,放在Redis里将是巨大的资源浪费,这些数据更适合存放在对象存储(如S3)或HDFS中。
-
需要复杂关系查询的数据: Redis不支持SQL那样的关联查询(JOIN)、复杂条件查询(WHERE子句)和事务的强一致性,如果你的业务逻辑严重依赖这些关系型数据库的特性,那么用Redis来存储主数据会非常吃力,甚至需要自己在应用层实现复杂的逻辑,得不偿失。
-
数据量巨大且价值不高的场景: 比如要存储全站所有用户的浏览历史,如果每个用户的历史记录都很长,总数据量可能达到数百GB,虽然这个功能很有用,但将其全部存在昂贵的内存里,性价比可能很低,可以考虑使用Redis存储最近的热点浏览记录,而将全量历史存储在更经济的存储中。
使用Redis的精髓在于“扬长避短”。 它的“长”是速度和丰富的数据结构,适合处理高并发、实时性要求的“热”数据和小型消息流,它的“短”是存储成本和对复杂查询的支持,在架构设计时,应始终将其定位为加速应用性能的“缓存”或“辅助存储”,与传统的持久化数据库搭配使用,各司其职,这样才能最大化其价值,避免资源浪费。

本文由帖慧艳于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/75814.html