红色的梯子上攀爬Redis集群那些难题和塔尖上的复杂纠结

基于阿里云开发者社区的一篇文章《攀登Redis集群的高峰:挑战与解决方案》以及个人实践经验进行阐述)

想象一下,你要爬一架红色的梯子,这架梯子很高,目标是要到达顶端去取一颗闪闪发光的宝石,这架红色的梯子,就是Redis集群,它看起来很壮观,能带你到达很高的地方(处理海量数据和高并发),但攀爬的过程,绝不像看起来那么轻松,你会遇到各种各样的难题,越往上爬,风越大,梯子晃得越厉害,这就是塔尖上的那些复杂纠结。
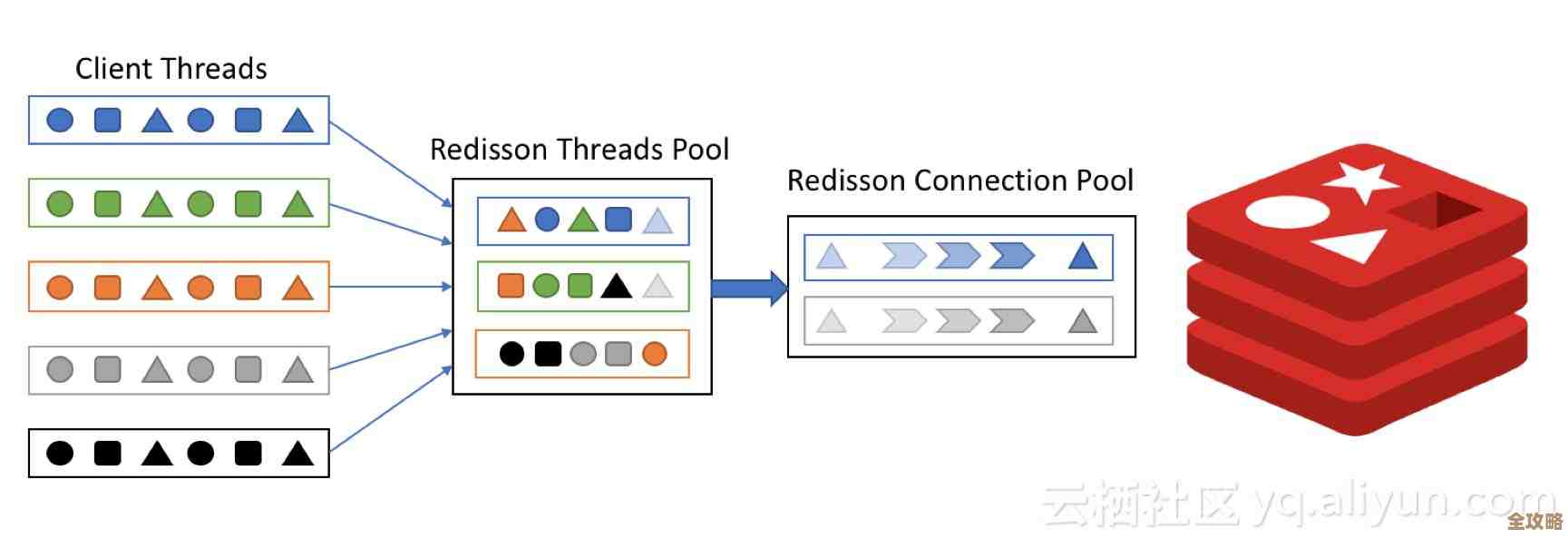
第一个难题就是,这架梯子不是一根完整的杆子,而是由很多节短梯子拼接起来的,这就带来了第一个麻烦:钥匙应该放在哪一节梯子上?(这里对应的是数据分片问题),在单机的Redis里,你所有的钥匙都放在一个口袋里,想拿哪把就拿哪把,但在集群里,你的数据被分散存放在不同的节点(那一节节的短梯子)上,系统会根据钥匙的名字算出一个值,就像根据钥匙的形状决定它适合哪个锁孔一样,然后把它放到对应的节点里,问题来了,有时候你需要同时操作好几把钥匙(比如先把用户的钱包扣掉,再给他的物品栏增加一件道具),如果这些钥匙很倒霉地被计算后放在了不同的节点上,那么你就无法保证这些操作能像一个整体一样要么全成功、要么全失败,这就是所谓的“跨节点事务”难题,你不得不小心翼翼地设计你的钥匙命名,想办法让那些需要一起操作的钥匙能被算到同一个节点上去,但这本身就很伤脑筋。

你继续往上爬,遇到了第二个难题:梯子会晃动,有时甚至会有一节梯子突然变得不太稳。(这对应的是节点故障与高可用性问题),Redis集群设计得很好,每一节短梯子(主节点)都配了一节备用的梯子(从节点),当主梯子明显断掉时,备用的梯子会接替它,但生活总不是完美的,有时候主梯子不是断了,而是变得“反应迟钝”(网络延迟高或者本身负载过高),这时候,整个系统可能误判它已经坏了,从而让备用梯子顶上来,可万一原来那节主梯子其实没坏,只是反应慢了点呢?这下可就热闹了,两节梯子都以为自己是主力,数据就可能乱套,这就是令人头疼的“脑裂”问题,虽然集群有机制来处理,但这始终是一个需要警惕的风险点。
当你费尽力气,快要接近塔尖时,你会发现最难的部分来了:梯子的顶端非常纤细,而且好几节梯子在这里交织在一起,让你不知该如何下脚。(这对应的是集群运维与扩展的复杂性),你觉得梯子不够高了,想再加一节新的梯子进去(扩容),或者觉得梯子太多了,想拆掉一节(缩容),这个过程叫做“重新分片”,这可不是简单地把新梯子绑上去就行,它意味着原来放在各节梯子上的钥匙,要有一部分被重新计算,然后搬到新梯子上去,这个搬家过程是非常小心翼翼的,如果期间有客户端还在不停地读写数据,很容易就会拿到旧的数据或者写丢数据,虽然工具能帮你做,但你需要选择在业务低峰期进行,并且严密监控,整个过程就像在给高速行驶的汽车换轮胎。
再比如,监控这架高高的红梯子本身也是个挑战,在单机时代,你只需要盯着一个点看它的状态(CPU、内存、网络),你得同时盯着几十个甚至几百个节点,每个节点是否健康?数据分布是否均匀?有没有哪节梯子特别热(热点Key问题),大家都去爬它,导致它不堪重负?这些监控的复杂度和报警的处理,都成倍地增加了。
塔尖上最纠结的可能是“连接管理”,客户端要连接这个集群,它不能只认一个入口,它必须知道整个梯子的结构图(集群拓扑),万一这个结构图变了(比如某节梯子换了位置),客户端如果不能及时拿到最新地图,就会朝着错误的方向爬,结果就是找不到钥匙,导致操作失败,一个聪明的、能自动感知集群变化的客户端库至关重要,但这又把一部分复杂性转移到了应用程序这一边。
攀登Redis集群这座红色的高梯,确实能让我们到达单机Redis无法企及的高度和承载力,但这一路上的挑战是实实在在的:如何优雅地处理分散在各处的数据?如何保证在部分梯子出问题时系统还能稳如泰山?如何在不停机的情况下安全地调整梯子的结构?以及如何清晰地掌控整个梯子集群的健康状况?这些难题和塔尖上的纠结,正是从简单使用Redis到驾驭Redis集群所必须面对和克服的挑战,它不是一个简单的升级,而是一种架构思想的彻底转变。

本文由歧云亭于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/74115.html