想搞懂分布式Redis,面试才不会被问懵,掌握这点很关键

(引用来源:微信公众号文章“想搞懂分布式Redis,面试才不会被问懵,掌握这点很关键”)

想搞懂分布式Redis,面试才不会被问懵,掌握这点很关键,这篇文章的核心观点是,理解分布式Redis的关键不在于死记硬背一堆命令或者配置参数,而在于掌握其最核心的设计思想——数据分片与高可用,理解了这两个核心,就像拿到了解开分布式Redis所有谜题的钥匙。
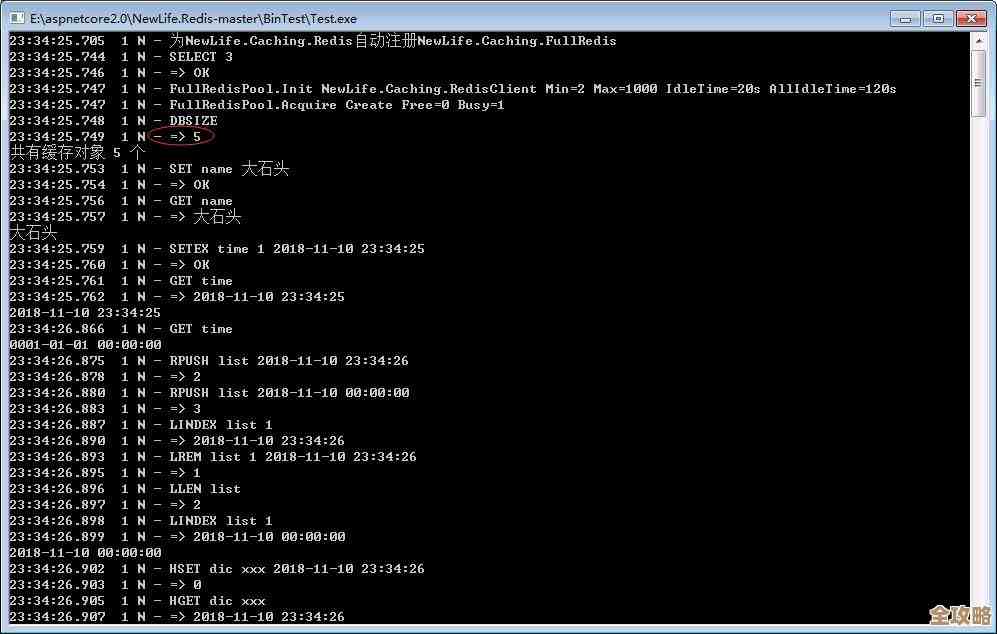
我们来说说为什么需要分布式Redis,你可以把单个Redis服务器想象成一个超级能干的仓库管理员,他处理货物的速度非常快,当需要存储的货物(也就是数据)多到他的仓库(内存)都装不下时,或者来提货送货的客户(请求)多到他一个人根本忙不过来时,这个管理员就算再厉害也会崩溃,这时候,我们就不能只依赖这一个管理员了,需要请来多个管理员,组成一个团队来协同工作,这个“团队”就是分布式Redis集群。

这个团队如何分工协作呢?这就引出了最核心的概念之一:数据分片,文章里强调,这是面试中最容易被深入追问的地方,数据分片就是“把一大筐鸡蛋分到多个篮子里”,在Redis里,“鸡蛋”就是一条条的数据,“篮子”就是一个个的Redis服务器节点,你不能随便乱放,得有个规则,保证每次存数据或者取数据的时候,都能准确地知道这个数据在哪个篮子里,Redis集群采用了一种叫做哈希槽的机制来实现分片,它预先准备了16384个编号的“小格子”(哈希槽),然后把这些小格子相对均匀地分配给集群里的每个主节点,当你存一个数据时,会用一个简单的算法算一下这个数据的键,算出它应该属于哪个小格子,然后就把数据存到管理那个小格子的节点上,这样,所有的数据就被分散存储到了不同的节点上,每个节点只负责一部分数据,压力就小多了,因为数据是分散的,所以总的存储量也变大了,突破了单机内存的限制。
光有分片还不够,万一某个“篮子”不小心掉地上了(也就是某个节点宕机了),里面的“鸡蛋”不就全碎了吗?另一个同等重要的核心概念就是高可用,分布式Redis必须保证即使有节点出故障,整个系统还能继续提供服务,并且数据不会丢失,这是怎么做到的呢?文章指出,Redis集群采用了主从复制的架构,简单说,就是给每个主节点(负责存数据干活的“主力管理员”)配一个或多个从节点(“备用管理员”),主节点做的所有操作,都会自动同步给它的从节点,这样,主节点这里就有一份完整的数据,从节点那里也有一份完整的备份,一旦主节点因为某种原因宕机了,集群就会自动从它的从节点中选举出一个新的主节点,来接替工作,这个过程是自动的,对于使用Redis的应用程序来说,可能只是感觉网络稍微卡顿了一下,然后就能继续正常访问数据了,几乎感知不到故障的发生,这就实现了高可用性。
文章特别提醒,理解主从切换的细节和可能存在的问题,是面试官考察你是否真正理解高可用的重点,可能会问在切换的瞬间,会不会有数据丢失的风险?这涉及到主从同步是异步还是同步的问题,Redis默认是异步复制,意思是主节点写完数据后,会立刻告诉客户端“写成功了”,然后再去同步给从节点,如果在这个同步的间隙主节点宕机了,那么还没来得及同步的这部分数据就可能丢失,虽然概率低,但这是分布式系统在设计上需要权衡的问题,面试官可能就是想看你是否了解这种权衡和潜在的风险。
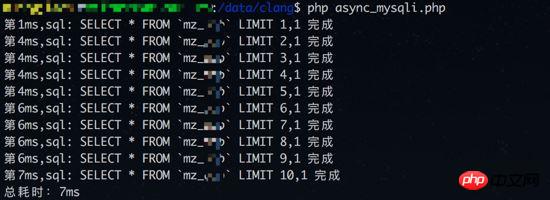
除了数据和可用性,文章还提到了客户端在分布式集群中是如何工作的,客户端不能像连接单个Redis那样随便连一个节点就行了,它需要先获取一份“集群槽位分布图”,也就是知道哪个编号的槽由哪个节点管理,然后客户端在发送命令前,自己先根据键算出槽位,再直接连接到正确的节点上进行操作,这减少了不必要的网络转发,提高了效率,这也解释了为什么在Redis集群中,有些涉及多个键的操作(比如同时处理两个键的交集)会受到限制,因为这两个键很可能不在同一个节点上,跨节点的操作会非常复杂。
这篇文章的核心思想就是:想不在分布式Redis的面试中被问懵,你就得紧紧抓住“数据分片”(如何把数据分散开以突破单机限制)和“高可用”(如何通过主从复制和自动故障转移保证服务不中断)这两个基本点,理解了它们为什么存在、如何工作以及可能存在的问题,你就能有条理地应对大部分相关问题,而不是零散地背诵一些知识点,这就像有了一个清晰的路线图,无论面试官问到哪里,你都能知道这个问题在整个分布式体系中的位置和意义。

本文由盘雅霜于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/72843.html