Redis编码机制深挖和那些隐藏的编码方式其实挺有意思,看看redis到底怎么存数据

主要综合自《Redis设计与实现》一书、Redis官方文档以及部分技术博客的深入分析,如Antirez(Redis创始人)的博客旧文)
Redis之所以快,除了因为它在内存中操作之外,还有一个非常重要的秘密武器,就是它精巧的编码机制,Redis并不是傻乎乎地用同一种结构存储所有的数据,它会根据你存入的每一个值的具体情况,比如数据的类型、长度、内容等,智能地选择一种最节省内存、访问效率最高的数据结构来存储,这个选择的过程对使用者是完全透明的,你感觉不到,但正是这些“隐藏”的编码方式,让Redis在性能和内存消耗之间取得了极佳的平衡。
就拿我们最常用的String类型来说吧,你可能以为所有的字符串都是简单粗暴地用一个字符数组来存的,其实不然,Redis会动很多“小心思”,当你存储的是一个整数,并且这个整数在8字节有符号整数范围内时,Redis就不会把它当成字符串存,而是直接用一个8字节的long型整数来存储,这样做的好处是,不仅存储空间更小(不需要存储字符串结束符之类的元数据),而且当你对这个值进行自增自减操作时,CPU可以直接进行整数运算,速度极快,省去了字符串转整数再转回来的开销。
再比如,如果你存储的字符串长度很短(比如小于等于44字节,这个阈值在不同Redis版本可能有变化),Redis会使用一种叫embstr的编码方式,这种方式会把Redis对象的结构头和字符串内容紧紧地分配在同一块连续的内存里,这样做能减少内存碎片,并且因为数据在一块连续内存上,CPU缓存的命中率更高,访问速度自然就上来了,但如果字符串长度超过了这个阈值,Redis就会改用raw编码,也就是老老实实地分配两块内存,一块存对象头,一块存字符串内容。
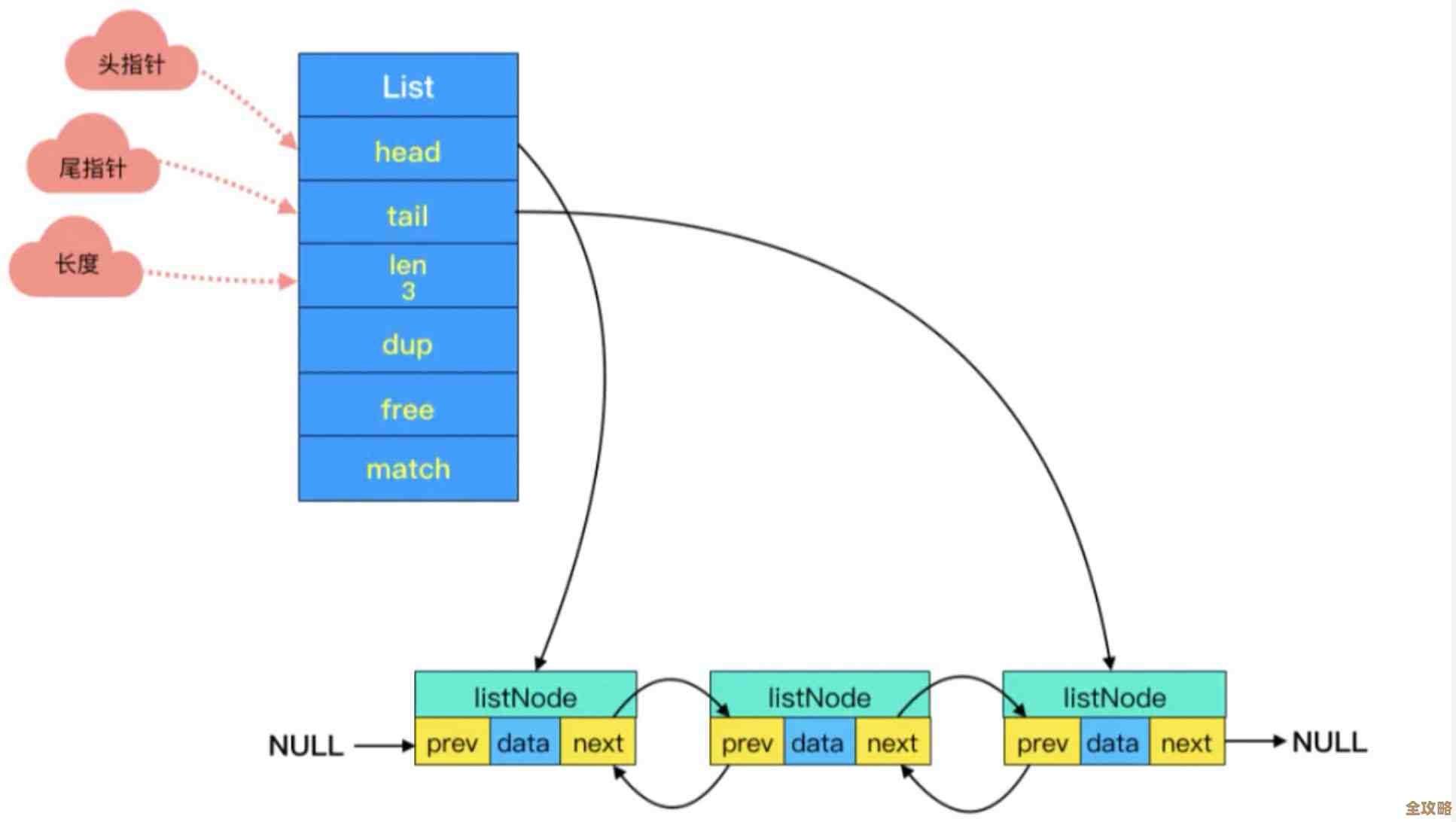
List列表的编码方式更有意思,早期版本的Redis列表底层都用链表实现,后来为了节省内存,引入了ziplist(压缩列表),ziplist是一块连续的内存空间,里面紧凑地存放了列表的所有元素,想象一下,如果一个小列表里的每个元素都像链表那样需要存前后指针,那这些指针本身就会占掉很多内存,很不划算,ziplist通过牺牲一点修改操作的性能(因为插入删除可能需要重新分配内存和移动数据),换来了极大的内存节约,只有当列表元素数量超过一定值,或者某个元素的大小超过一定阈值时,Redis才会将这个列表从ziplist“升级”为标准的双向链表linkedlist,以应对更复杂的操作。
Hash哈希对象的编码策略也类似,当哈希中的字段数量很少,且每个字段名和字段值都是小字符串时,Redis会使用一种名为ziplist的编码(和列表用的那个是类似结构),它也是将所有字段和值交替着、紧凑地存放在一块连续内存里,这种方式对于存储大量的小对象(比如用户会话信息、对象属性等)节省的内存是惊人的,一旦数据量变大或者出现了大value,它就会自动转成标准的哈希表(hashtable)结构。
Set集合和Zset有序集合也不例外,Set在小数据量时使用一种叫intset的编码,专门用于存储整数,效率极高,Zset在小数据量时则使用ziplist,按分值排序紧凑存储。
这些自动转换的阈值是可以通过Redis的配置文件进行调整的,这意味着你可以根据自己业务数据的特点,来“调教”Redis,让它在你最常用的数据规模下,尽可能使用内存效率最高的编码方式。
说Redis是个“智能”的数据库一点也不为过,它不像很多数据库那样用一种固定的“尺码”去套所有的数据,而是像一位经验丰富的裁缝,为每份数据“量体裁衣”,我们平时只用简单的SET、GET、HSET等命令,背后却是Redis在默默地为我们优化存储,在内存这个寸土寸金的地方精打细算,深入理解这些隐藏的编码机制,不仅能帮助我们更好地理解Redis的工作原理,当遇到性能瓶颈或内存问题时,也能为我们提供更清晰的排查思路和优化方向,这大概就是Redis设计的精妙和有趣之处。

本文由歧云亭于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/71652.html
相关文章
-
MySQL报错ER_KEYRING_ENCRYPTED_FILE_DECRYPTION_FAILED导致解密失败,远程帮忙修复故障方案
-
Redis键删除策略帮你省缓存资源,配置起来其实没那么复杂
-
ORA-48449错误,尾部告警只能针对单个ADR家目录,远程帮忙修复故障问题
-

用PyCharm怎么弄Flask项目还能顺带连上数据库,边写代码边调试那种感觉
-

树叶云数据库里MySQL的root账号密码改成普通用户密码怎么弄,步骤讲解分享
-
多云环境下机器ID安全那些事儿,技术手段其实没那么简单
-
Redis槽道迁移带来更多可能性,拓展了redis使用的新空间和新玩法
-
Redis学着学着就发现,实践才是最好的老师,总结经验别忘了跟上节奏



