Redis里ZADD命令超时问题到底是咋回事,深入聊聊那些细节和坑

最核心的一点是,ZADD命令本身是一个非常高效的命令,它的时间复杂度是O(log(N)),其中N是排序集合中的元素数量,理论上,对于一个包含百万甚至千万级元素的集合,单次ZADD操作也应该是毫秒级别完成的,当你遇到ZADD超时,比如Redis日志里出现了“slowlog”慢查询记录,或者客户端收到了超时错误,这通常不是一个简单的“数据量大”的问题,而是背后有更深层次的原因,咱们得往细了挖。
第一个大坑:巨大内存分配导致的延迟
这是最常见也是最隐蔽的一个原因,虽然ZADD是O(log(N)),但这个复杂度是基于理想情况的,想象一下,你往一个已经很大的有序集合里,一次性插入成千上万个新成员(比如通过管道一次性提交了一个巨大的ZADD命令),Redis需要为这些新成员分配内存,如果这个有序集合占用的内存非常大,比如几十个GB,那么这次大规模的内存分配操作可能会触发操作系统的“换页”或者导致Redis主线程被阻塞。
为什么?因为Redis是单线程模型,所有命令排队执行,当它需要分配一大块连续内存时,如果当前系统内存碎片化比较严重,操作系统可能需要花费很长时间去寻找和整理可用的内存空间,这个过程中,Redis的主线程就只能干等着,无法处理其他任何请求,从客户端的角度看,就是这次ZADD命令“卡住”了,超时了,这种情况在高内存使用率的实例中尤其明显,参考来源:Redis官方文档对延迟问题的分析中,多次提到大内存分配和内存碎片是导致延迟 spikes(尖峰)的主要原因之一。
第二个坑:触发了持久化操作的时机
Redis为了数据不丢,有RDB快照和AOF日志两种持久化方式,如果ZADD命令执行的时候,正好撞上了以下两种情况,就很容易超时:
-
生成RDB快照(BGSAVE):当手动执行BGSAVE或自动触发快照条件时,Redis会fork一个子进程来生成RDB文件,如果此时你的Redis实例占用了很大内存(比如20GB),fork操作本身可能会非常耗时,在fork的瞬间,虽然子进程与父进程共享内存,但操作系统需要复制父进程的内存页表,这个操作在主线程中执行,内存越大,复制页表所需的时间就越长,在这期间,主线程是阻塞的,无法处理新命令,如果你的ZADD命令恰好在这个时间点前后到来,就会经历漫长的等待,参考来源:Redis持久化文档明确说明了fork在内存过大时可能引起的延迟问题。
-
AOF重写:AOF重写同样会fork子进程,所以上面fork的问题它也有,更关键的是,AOF通常配置为“每秒同步”或“每次操作同步”,如果配置了“always”(每个写命令都同步刷盘),那么每个ZADD命令都要等待磁盘写入完成才返回,如果磁盘IO压力大,延迟自然就上去了,即使是“everysec”,在同步的那一刻也可能有轻微延迟。
第三个坑:网络和客户端层面的问题
问题并不在Redis服务器本身,而是在网络或客户端。
- 大数据量的响应:你执行的不是一个简单的ZADD,而可能是一个返回值的ZADD命令(比如ZADD ... CH ...),或者你通过管道(pipeline)一次性发送了海量的ZADD命令,虽然服务器处理得快,但网络传输结果需要时间,如果结果集非常大,网络带宽又有限,客户端读取响应数据流就会很慢,导致客户端设置的读写超时被触发。
- 客户端阻塞:你的应用程序在发出ZADD命令后,可能因为自身原因(比如Full GC垃圾回收)被阻塞了,没有及时去读取Socket缓冲区里Redis返回的响应,等它缓过神来,可能已经超过了Socket自己设置的超时时间。
第四个坑:Redis实例的整体压力
你的ZADD命令可能只是个“受害者”,如果Redis实例的CPU持续100%,或者内存耗尽开始使用Swap,或者有其他非常耗时的命令(比如keys *, 或者对一个大集合执行hgetall)正在执行,那么整个实例的处理能力都会下降,所有命令,包括原本很快的ZADD,都需要排队等待,排队时间过长就超时了。
怎么排查和避免?
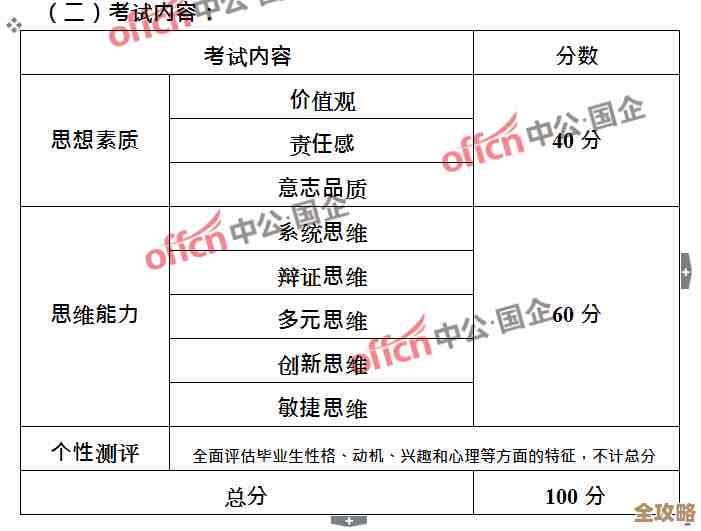
- 查看慢查询日志:使用
SLOWLOG GET命令,看看超时的ZADD命令到底执行了多久,以及当时有没有其他慢命令。 - 监控系统资源:密切关注Redis服务器的内存使用率、内存碎片率、CPU使用率以及磁盘IO(如果开了AOF),特别是内存碎片率,如果过高(gt;1.5),可以考虑在业务低峰期执行
MEMORY PURGE(新版)或重启实例来整理。 - 优化命令使用:
- 避免单次插入海量数据,可以拆分成小批量进行。
- 谨慎使用会返回大量数据的选项。
- 对于非实时性要求高的数据,可以考虑使用管道(pipeline)减少网络往返,但要控制好单次管道的数据量。
- 调整持久化策略:如果fork是主要问题,可以考虑在从库上做持久化,主库关闭持久化,或者优化RDB快照的触发条件,避免在业务高峰触发。
- 升级硬件/架构:如果数据量确实巨大,考虑使用更高配置的机器(更快的CPU、更大的内存、SSD硬盘),或者使用Redis集群将数据分片,分散压力。
ZADD超时很少是它自身的“错”,它更像是一个信号,提醒你Redis实例的整体环境可能出现了问题,比如内存分配、持久化fork、资源竞争等,排查的时候一定要有全局视角。

本文由黎家于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/70172.html