数据库优化其实没那么复杂,主要就是这些步骤和方法你得了解清楚才行

(根据微信公众号“有关SQL”的文章《数据库优化其实没那么复杂,主要就是这些步骤和方法你得了解清楚才行》整理)
数据库优化这事儿,听起来好像特别高深,得是那种资深工程师才能碰的领域,但其实不然,只要你把思路理清楚了,按照一些基本的步骤和方法来,很多性能问题都能得到显著的改善,它不像变魔术,更像是一次有计划的体检和调理,关键是你得知道从哪里入手,以及每一步该干什么。

最重要的一步,不是让你一头扎进代码里改这改那,而是要先搞清楚问题到底出在哪儿,这就好比医生看病,得先问诊、检查,不能病人一说头疼就直接开止痛药,数据库也是这个道理,你得先找到那个“慢”的点,数据库自己就带了很多“体检工具”,比如慢查询日志,你把这个功能打开,它就会自动记录下来哪些SQL语句执行花了太长的时间,这就是你最直接的线索,你要做的就是定期去查看这个日志,把里面那些“榜上有名”的慢查询语句找出来,除了慢查询日志,很多数据库管理工具还能让你实时看到当前正在运行的SQL,哪些消耗了大量的CPU或者磁盘读写,这些也是重点怀疑对象。
找到了这些嫌疑很大的慢SQL之后,接下来就要对它们进行“解剖”,看看为什么慢,这里就要用到“执行计划”这个工具了,你可以让数据库告诉你,它打算怎么执行你写的这条SQL语句,它是打算全表扫描(就像在一本没有目录的书中一页一页地找内容),还是能通过索引快速定位(就像通过书的目录直接翻到某一页)?全表扫描是性能杀手,尤其是在数据量大的表上,通过看执行计划,你就能发现瓶颈所在:是不是因为没用到索引?或者是用的索引不对?还是说它在进行一种非常耗资源的操作,比如复杂的排序或者临时表的创建?

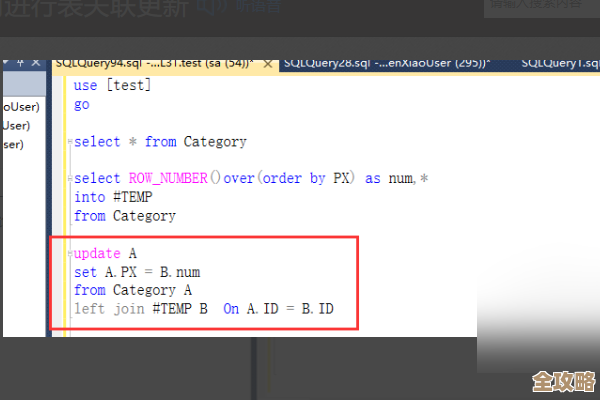
找到了原因,解决办法就相对明确了,最常见、也是最有效的手段之一就是“加索引”,索引就像是书本的目录,能让你快速找到想要的数据,避免漫无目的的全盘扫描,索引也不是越多越好,因为每增加一个索引,在插入、更新、删除数据的时候,数据库也需要额外去更新索引,这会带来一定的开销,加索引的原则是:针对那些经常被用来做查询条件的字段,特别是那些重复值不多的字段,给用户的身份证号字段加索引就比给性别字段加索引效果要明显得多。
除了加索引,另一个重要的方面是审视SQL语句本身写得怎么样,一条SQL语句写得不好,即使有索引也用不上,在查询条件里对字段进行函数操作(像WHERE YEAR(create_time) = 2023),就可能导致数据库无法使用create_time字段上的索引,这时候,把条件换个写法(WHERE create_time >= '2023-01-01' AND create_time < '2024-01-01'),可能性能就一下子提升了,还有就是避免使用SELECT *,只查询需要的字段,减少不必要的数据传输和计算。
当单条SQL的优化做到一定程度后,你可能需要从更宏观的角度来看问题,那就是数据库的设计和架构,考虑“读写分离”,就是把数据库分成主库和从库,主库主要负责接收数据的写入和更新,而从库则专门用来处理大量的查询请求,这样就把压力分摊开了,避免读写操作挤在一起互相影响,再比如,对于一些计算量特别大、但又不需要实时最新结果的统计报表,可以提前算好,存成一张“结果表”,这就是所谓的“缓存”或“预计算”思想,用空间换时间。
硬件和系统配置也是一个不能忽视的层面,如果数据库所在的服务器内存太小,频繁需要从磁盘读取数据,那肯定会慢,适当增加内存,让更多的数据可以缓存在内存里,速度会快很多,数据库软件本身也有很多配置参数,比如连接数、缓存大小等,根据实际业务量进行合理的调整,也能带来性能提升。
数据库优化其实是一个由表及里、由点到面的过程,核心步骤就是:先监控和发现慢查询,然后分析慢的原因(重点看执行计划),接着针对性地采取措施(比如优化SQL语句、添加合适的索引),最后再考虑架构和硬件层面的调整,只要你把这个流程记在心里,遇到性能问题时不慌张,一步步去排查和解决,就会发现,数据库优化真的没那么复杂。

本文由芮以莲于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/68546.html