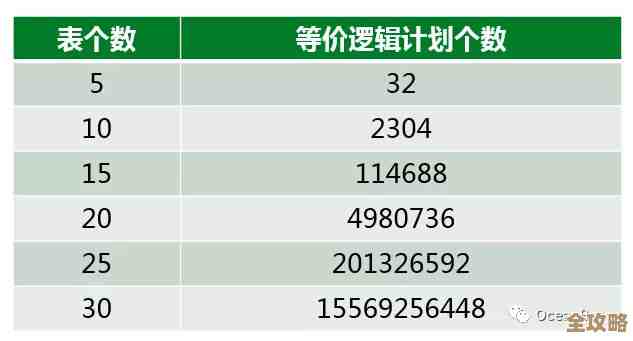
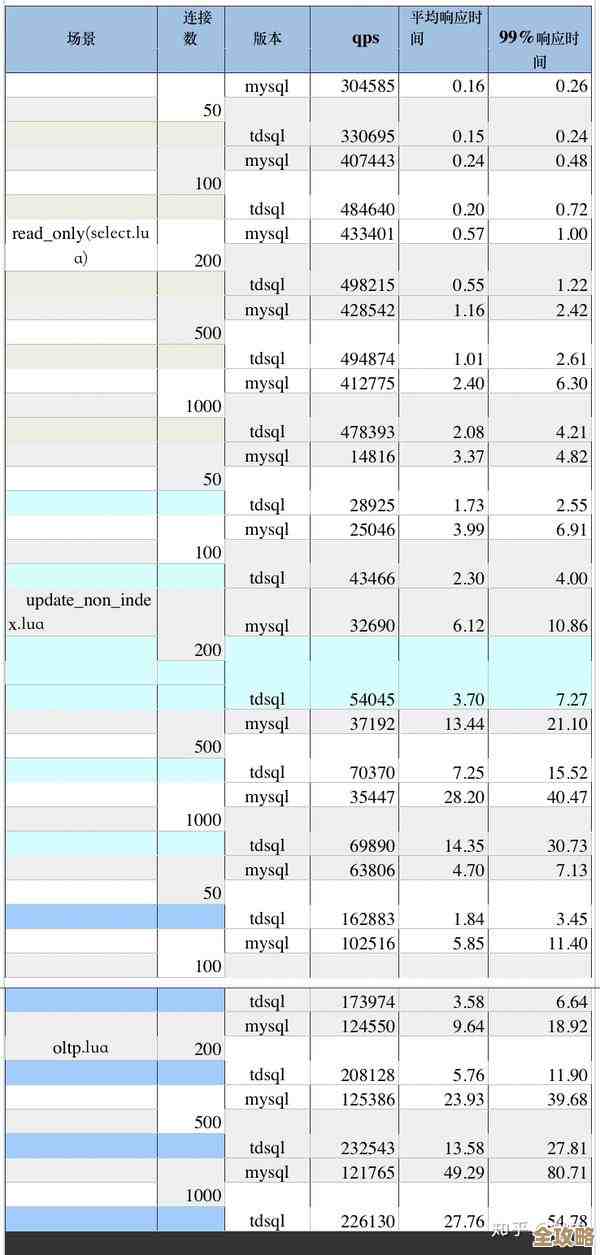
分布式事务终于搞明白了,之前一直糊里糊涂这回算是清楚点了

根据网络上多位技术博主和个人开发者的经验分享文章与讨论整理,特别是知乎、CSDN、掘金等平台上的高赞回复和系列教程)
我之前一直对分布式事务这个东西感觉很模糊,看书上的定义好像懂了,什么ACID、两阶段提交,名词都背下来了,但一到实际项目中,尤其是自己负责的微服务需要和别的服务一起完成一个操作时,就彻底懵了,不知道从何下手,脑子里一堆问号:我这个服务的事务该怎么弄?怎么保证别人家的服务也成功?万一他失败了,我这边已经做完的怎么办?难道要手动去数据库里改回来吗?那也太蠢了。
最近因为项目逼到眼前了,必须解决这个问题,我就下了狠心,找了好多资料看,也问了组里的大佬,总算是在一团乱麻里理出了个头绪,我不敢说精通,但至少现在知道它是个什么问题,以及有哪几条路可以走了,感觉就像一直隔着一层毛玻璃看东西,现在玻璃被擦亮了一点。
我最大的一个误区过去就是,老想着用一个“魔法”一样的技术,像本地事务(就是那个begin; ... commit;)一样,能一键搞定跨多个服务的数据一致性,后来才明白,分布式事务和本地事务根本是两码事,因为网络是不可靠的,你无法保证你调用另一个服务的时候,它一定在线,一定能成功,一定能给你返回结果,这个“不确定”就是所有问题的根源。

分布式事务的核心思路,其实不是去追求那种强一致性(就是像本地事务一样,瞬间大家都成功或都失败),而是通过各种办法,在“不确定”的环境中,最终让数据达到一致的状态,并且要保证系统的高可用性,不能因为一个服务挂了,整个流程就卡死,说白了,就是一种“妥协”和“兜底”的艺术。
我现在理解到的,解决分布式事务问题,主流有几种套路,我把它们想象成了现实生活中的场景,这样就好记多了。
第一种套路,叫“两阶段提交”(2PC)。 这个可以想象成一组人(比如几个部门)要一起做一个决定,比如周末是否团建,需要一个协调者(比如项目经理)。

- 第一阶段:询问阶段。 项目经理发邮件给每个人问:“周末团建,同意的回复Yes,反对回复No,必须回复!” 这个时候,每个人自己心里盘算(执行事务操作,但不最终拍板),然后回复Yes或No。
- 第二阶段:决策阶段。 项目经理收到所有人的回复,如果所有人都是Yes,他就发邮件说:“好,全员通过,团建照常,大家把钱交了(提交事务)!” 如果有任何一个人回复No或者超时没回复,他就发邮件说:“有人不同意,团建取消,大家该干嘛干嘛(回滚事务)。”
这个方法的好处是强一致,要么全成功,要么全失败,但缺点太明显了:效率低,要等所有人回应;协调者单点故障,项目经理要是中途手机没电了,大家就全傻等了;数据不一致风险,万一有人在第二阶段交钱的时候突然反悔,或者网络问题没收到通知,就会出乱子,所以现在用的少了,尤其是在高并发场景下。
第二种套路,叫“TCC模式”。 这个我觉着比2PC更实用,TCC是三个单词的缩写:Try、Confirm、Cancel,我把它想象成订机票和酒店的自由行套餐。
- Try阶段(尝试):相当于你把机票和酒店都先“占上”,锁定座位和房间,也冻结了你一部分信用卡额度,但这时候还没真正扣款,你还可以反悔,在系统里,这就是各个服务先检查资源,并预留好,比如库存服务先把库存-1(但状态是“已锁定”),积分服务先计算好要送的积分(但状态是“待生效”)。
- Confirm阶段(确认):如果你最终决定要这个套餐,旅游网站就会真正扣款,然后把机票和酒店的状态从“锁定”变成“已售出”,在系统里,如果所有服务的Try都成功了,就调用每个服务的Confirm接口,让之前的预留操作真正生效。
- Cancel阶段(取消):如果你不想买了,旅游网站就会把你锁定的座位和房间释放掉,信用卡额度解冻,在系统里,如果任何一个服务的Try失败(比如酒店没房了),就调用所有已经Try成功的服务的Cancel接口,释放资源。
TCC的好处是业务自己控制力度细,性能比2PC好,因为不需要长时间锁住所有资源,但缺点是要写很多代码,每个服务都要实现Try、Confirm、Cancel三个接口,对开发要求高。

第三种套路,也是我现在觉得最简单实用的,叫“可靠消息最终一致性”。 这个就像我们生活中的寄快递。
- 你想给朋友寄个礼物(完成一个业务),你首先自己把礼物打包好(在本地数据库完成操作,比如订单状态改成“已支付”),你写一张快递单(生成一条消息,内容就是“通知物流服务发货”),把这张单子先放在你家门口的“待寄件”篮子里(把消息存到本地数据库的专门消息表里,和你的业务操作在同一个本地事务里完成)。
- 你不用管了,你们家有个专门的快递员(一个后台任务),会定时去检查“待寄件”篮子,他看到有单子,就拿着单子和礼物去快递点寄出(把消息发送到消息队列,比如RabbitMQ、Kafka)。
- 物流服务(另一个微服务)就像快递点,它一直听着有没有新快递,它收到消息后,就开始处理发货(执行它的本地事务,比如创建运单),如果处理成功了,它就给快递点回个信说“收到了”(发送一个确认回执)。
- 万一快递员第一次送单子时路上把单子丢了(消息发送失败),或者物流系统暂时宕机了(消费失败),没关系!你们家的快递员过一会儿(比如5分钟后)还会再次检查篮子,发现那张单子还在“待寄件”状态,他就会重新再送一次(消息重试),这样一直重试,直到物流公司确认收到为止。
这个方法的核心就是“靠重试来保证最终会成功”,它牺牲了一点实时性(可能物流服务几分钟后才收到通知),但换来了系统的简单和鲁棒性(不容易挂掉),对于很多不那么要求瞬间一致性的业务(比如下单后通知积分、发短信),特别合适。
除了这三大类,还有一些别的办法,Saga模式”,就是把一个长事务拆成很多个小步骤,每个步骤都有对应的补偿动作,一步一步往前滚,失败了就一步一步倒回来。
这么一圈看下来,我算是明白了,没有一种方法是万能的,选择哪种方案,得看你的业务场景,你要是做银行转账,那可能得用TCC甚至更严格的方案;你要是做个电商下单,用“可靠消息最终一致性”就挺好的,简单又高效。
以前觉得分布式事务特别高深,现在发现它的思想其实很朴素,就是承认网络会故障、服务会挂掉这个现实,然后在这个现实基础上,设计出各种“后悔药”和“保险机制”,让系统在大部分时间能正常跑,在出问题时也能慢慢地、自动地恢复到一致的状态,搞明白了这一点,心里一下子就踏实多了,至少再遇到相关问题,我知道该往哪个方向去查资料、去和同事讨论了。
本文由革姣丽于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/68534.html