Kafka 高性能高可用高扩展性设计那些事儿,聊聊架构背后的秘密

综合自多位资深技术专家在社区分享、技术博客及行业实践案例的解读)
说起Kafka,它就像是大数据世界里的超级高速公路,专门负责运送海量的数据消息,它的三个最出名的特点就是高性能、高可用和高扩展性,那它到底是怎么做到的呢?咱们就抛开那些难懂的专业术语,聊聊它背后的一些设计秘密。
第一,高性能的秘密:顺序写磁盘和“零拷贝”
你可能觉得奇怪,数据写到磁盘上,速度能有多快?Kafka的妙招就是“顺序写”,普通数据库经常要随机找地方存数据,就像在停车场里找空位,很费时间,而Kafka呢,它把所有要来的新数据,就像排队一样,一个接一个地只追加到文件的末尾,这种顺序写入磁盘的速度,其实非常快,甚至能赶上内存操作的速度。
光写进去快还不够,读出来也要快,这里就用到了“零拷贝”技术,简单打个比方,正常情况下,数据从硬盘读到应用手里,需要经过好几次“倒手”:先从硬盘拷贝到操作系统内核的缓冲区,再从内核缓冲区拷贝到应用程序的内存空间,应用程序处理完可能还要再拷贝回去,非常繁琐,Kafka通过利用操作系统的特性,实现了“零拷贝”,意思是数据直接从硬盘拷贝到网卡缓冲区,然后通过网络发出去,省去了中间在应用内存里来回折腾的步骤,这样一来,CPU的负担大大减轻,网络传输的效率也极高,这就是为什么Kafka能轻松处理每秒几十万、上百万条消息的秘诀之一。
第二,高可用的秘密:分区和多副本

高可用就是说,即使机器出故障了,整个系统也不能停摆,Kafka实现这一点,靠的是“分区”和“副本”机制。
Kafka的一个主题(可以理解为一个数据流类别)可以被分成多个“分区”,这好比一条大路分成了好几个车道,数据被分散到不同的车道上流动,这样做的好处是,首先可以并行处理,提高吞吐量;更重要的是,实现了负载分散,一个分区出问题不影响其他分区。
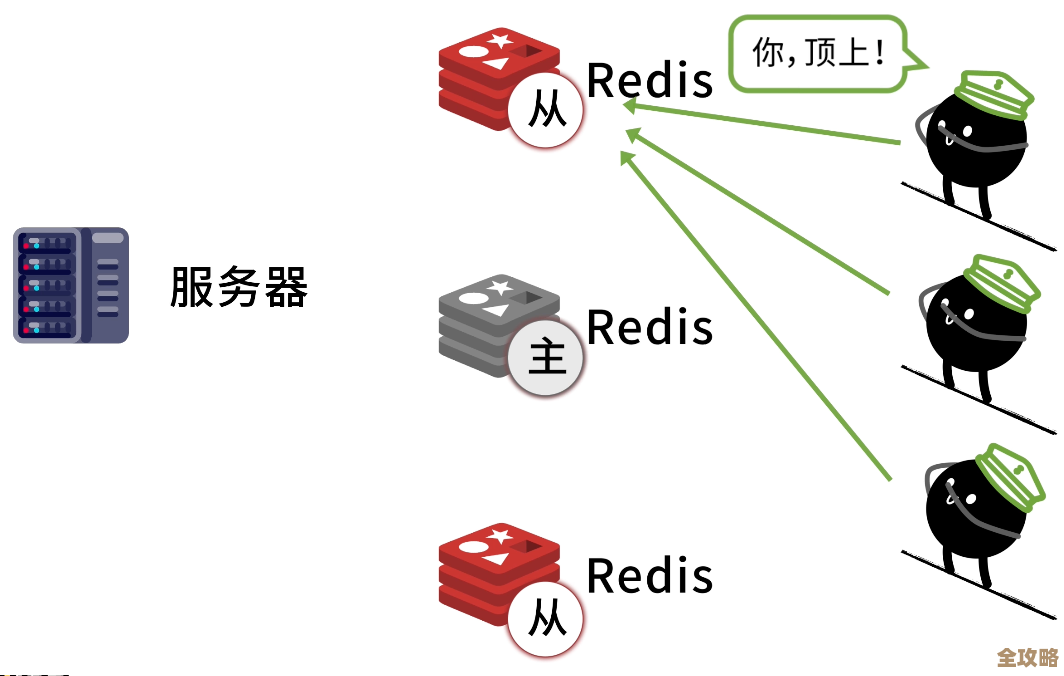
但只有一个分区还不够保险,万一这个分区所在的服务器宕机了,数据就丢了,服务也中断了,所以Kafka为每个分区创建了多个副本(通常三个),这些副本分散在不同的服务器上,这些副本里,有一个是“首领”,负责所有的读写操作;其他的是“追随者”,它们会不停地从首领那里同步数据,保持数据一致,一旦首领所在的服务器挂了,Kafka会立马从追随者中自动选举出一个新的首领,继续提供服务,对整个系统来说,这个过程是自动的,用户几乎感觉不到中断,这就好比一个团队的领导突然请假了,立刻就有备用的副手顶上去,团队工作照常进行。

第三,高扩展性的秘密:朴素的“加机器”哲学
高扩展性指的是当数据量变大或者访问压力增加时,系统能通过增加机器来轻松应对,Kafka在这方面的设计非常直接:需要更大的处理能力?加机器就行了。
因为Kafka的主题是分区的,而分区可以分布在集群中任意多的服务器上,当我觉得吞吐量不够了,或者存储空间不足了,我只需要简单地往集群里添加新的服务器(Broker),然后通过工具把一部分分区的副本迁移到新机器上,就能平衡负载,这个扩展过程可以在系统不停机的情况下平滑进行,由于Kafka的元数据由ZooKeeper(一个协调服务)统一管理,新加入的机器能很快被集群识别和接纳,这种设计使得Kafka集群可以轻松地从几台机器扩展到上百台甚至上千台机器,线性地提升整体的处理能力。
总结一下
Kafka的高性能源于它“顺序写磁盘”和“零拷贝”这种最大化利用硬件能力的聪明设计;高可用依赖于“分区”和“多副本”机制带来的冗余和自动故障转移;高扩展性则得益于其分区的架构,让“通过加机器来解决问题”变得简单可行,这些设计思想环环相扣,共同造就了Kafka作为现代数据管道核心的稳固地位,它背后的秘密,其实就是用简单而有效的架构思路,去解决复杂的大规模数据流难题。
本文由雪和泽于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/67560.html