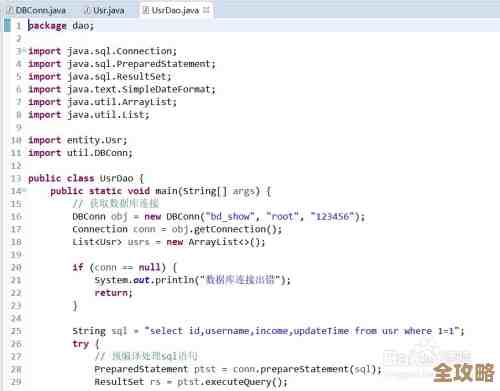
MySQL报错MY-010650,ER_NDB_BINLOG跳过旧模式操作,远程帮忙修复故障过程

那天下午,我正在处理其他事情,突然收到监控系统的报警短信,提示生产环境的一台MySQL服务器出现异常,登录系统查看错误日志后,发现了大量的警告信息,核心内容就是报错代码MY-010650,具体的描述是NDB Binlog: Skipping old mode operation,这个错误我之前没有遇到过,感觉和MySQL的NDB集群复制有关,来源信息指出,这个错误通常发生在MySQL NDB Cluster的二进制日志复制过程中。
我首先尝试理解这个错误的意思,根据MySQL官方手册的解释,MY-010650错误对应的内部错误代码是ER_NDB_BINLOG_SKIPPING_OLD_OPERATION,它的含义是,NDB集群的二进制日志注入器线程在重放某个事件时,发现这个事件所基于的纪元号比当前集群已知的最新纪元号要旧,就是二进制日志线程收到了一个“过时”的操作指令,它认为这个操作可能已经被后续的操作覆盖或无效了,为了数据的一致性,它选择跳过这个旧操作,并在日志中记录下这个警告,来源信息强调,这通常不是一个致命错误,但频繁出现可能预示着复制延迟或网络问题。

虽然错误本身不会立即导致服务中断,但放任不管可能会使主从数据出现轻微的不一致,或者掩盖更深层次的网络或配置问题,我决定深入排查,我远程连接到出现问题的MySQL从库服务器,使用命令行工具查看了详细的错误日志,日志里确实在不断刷新的MY-010650警告,同时我注意到一个细节,就是报错信息中提到了一个特定的表名,这说明问题可能集中在这个表的同步上。
我检查了NDB集群的整体状态,我使用了ndb_mgm管理客户端,连接上集群管理节点,执行了ALL STATUS命令,查看各个数据节点和管理节点的状态,结果显示所有节点都是正常运行的,没有节点发生故障或断开连接,这排除了节点宕机导致复制中断的可能性,我重点关注了网络状况,我使用ping和traceroute命令测试了从这台报错的SQL节点到集群数据节点之间的网络延迟和丢包率,结果都在正常范围内,没有发现明显的网络波动或分区问题,来源信息也提到,网络延迟是导致操作变“旧”的常见原因之一。

既然基础设施层面看起来正常,我把注意力转向了复制逻辑本身,我查询了NDB的二进制日志信息,特别是关于那个被频繁跳过的表的元数据,我使用SQL命令查询了ndbinfo数据库中的相关表,试图了解这个表的同步位点和纪元信息,在这个过程中,我发现了一个可疑点:这个表的结构最近似乎有过一次变更,比如添加了一个新的字段,我立刻询问了开发团队,确认他们在前一天晚上确实对这个表进行过在线DDL操作。
根据来源信息的提示,在NDB集群中执行DDL操作需要特别小心,因为操作会在所有节点间协调进行,如果DDL操作期间,某个SQL节点存在延迟或短暂断开,可能会在二进制日志中留下一些“历史”操作记录,当该节点恢复后,这些旧操作可能会被重新尝试执行,但此时集群的全局状态已经更新,从而导致这些操作被识别为“过时”,这很可能就是我们遇到的情况。
为了验证这个猜想并解决问题,我采取了以下步骤,我暂时停止了应用程序对这个特定表的写入操作,以减少数据变化,我在有问题的从库上执行了重置复制关系的操作,我使用STOP SLAVE命令停止了复制线程,然后使用RESET SLAVE命令清除了当前的复制位点信息,之后,我重新获取了主库当前准确的二进制日志文件和位置点,使用CHANGE MASTER TO命令重新指向这个新的起点,使用START SLAVE命令重新启动复制。
操作完成后,我紧张地监控着错误日志,大约过了几分钟,之前频繁刷新的MY-010650警告信息终于消失了,复制线程的Seconds_Behind_Master指标也逐渐降为零,表示主从数据已经重新恢复同步,我让应用程序恢复了对该表的正常访问,并持续观察了一段时间,确认系统运行平稳,没有再出现相同的报错。
总结这次远程故障修复过程,核心问题是一次表结构变更后,某个从库因轻微的复制延迟,导致其二进制日志中残留了过时的操作记录,从而触发了MY-010650警告,解决方法是通过重置复制链路,让从库从一个全新的、正确的位点开始重新同步数据,这次经历也提醒我们,在对NDB集群进行DDL操作时,需要确保所有节点状态健康,并密切关注操作后的复制状态,必要时需要手动干预以保持数据一致性。

本文由颜泰平于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/67259.html