CPU架构深度剖析:探索新一代处理器的设计奥秘与性能阶梯

你肯定听过什么x86、ARM对吧?这俩老冤家,就像…就像两个完全不同哲学流派的武林高手,x86呢,像是名门正派,招式繁多,内力深厚,但有时候显得有点笨重,包袱重啊,它那套复杂指令集(CISC),初衷是想让编译器少干点活,一条指令干一堆事,结果呢,指令越来越复杂,解码起来贼费劲,就像一本厚厚的说明书,你得先翻半天才能明白这条指令到底要你干嘛,所以你看现代的x86处理器,前端第一个活儿就是把那些复杂的指令“翻译”成更简单、更规整的微操作(μops),这本身就是个巨大的能耗和延迟开销,但没办法,历史包袱太重了,几十年的软件生态都建在上面,船大难掉头。
ARM呢,走的是另一条路,像是个精干的刺客,讲究一招制敌,效率至上,精简指令集(RISC)的理念就是,指令本身很简单,绝大多数指令在一个时钟周期内就能完成,这样解码器就轻松多了,结构可以做得更简洁,更省电,所以你看手机、平板,几乎都是ARM的天下,功耗控制是命根子嘛,但你也别觉得ARM就永远轻盈,现在性能上来了,要跟x86在服务器、甚至桌面领域掰手腕,它也不得不加入一些更复杂的玩意儿,比如更宽的解码、更深的乱序执行窗口,也开始有点“发福”的迹象了,这就像…嗯,一个原本清瘦的修行者,为了打擂台,也开始练肌肉了,难免会失去一点最初的纯粹。😂
说到性能阶梯,我觉得最迷人的就是那个“乱序执行”(Out-of-Order Execution),这真是个鬼才想法!早期的CPU是顺序执行的,一条指令卡住了,后面全得等着,干着急,乱序执行呢,就像个超级聪明的管家,它瞅着眼前一堆任务(指令),发现“哦,你去烧水需要10分钟,你去切菜只要2分钟,但切菜不依赖烧水的结果”,那它就会让切菜的先做,哪怕烧水的指令写在前面,CPU内部有个叫“重排序缓冲区”(ROB)的东西,像个调度中心,时刻盯着哪些指令的操作数准备好了,就立刻派去执行单元干活,最后再按原始顺序把结果提交回去,保证程序逻辑没错,这背后是巨大的硬件开销,但换来的性能提升是革命性的,也带来了像“幽灵”(Spectre)这种侧信道攻击的安全漏洞,真是有一利必有一弊啊。
还有缓存,这玩意儿简直是性能的生命线,CPU速度比内存快太多了,直接等内存送数据过来,CPU大部分时间都在那“空转”,等得花儿都谢了,所以就有了L1、L2、L3缓存,像一套越来越大的临时仓库,L1最小最快,紧贴着核心,专供核心自己用;L2大一点,慢一点,可能几个核心共享;L3更大更慢,所有核心共享,数据在哪一级缓存里命中,对延迟影响天差地别,设计缓存就是个平衡艺术,容量、速度、关联度、一致性协议… 搞不好就会成为瓶颈,有时候你看到两个CPU核心频一样,但实际性能差一截,很可能就是缓存架构的差异,这感觉就像,两个司机开一样快的车,但一个总是知道最近的捷径(缓存命中率高),另一个老在绕远路(缓存命中率低)。
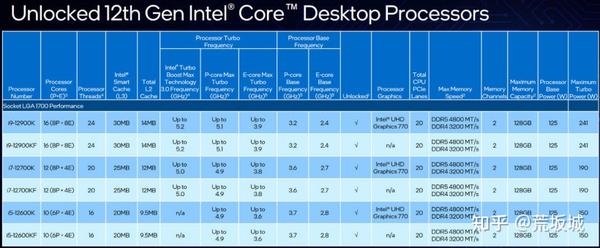
现在的新一代处理器,像苹果的M系列、AMD的Zen系列、Intel的混合架构,玩的花样就更深了,苹果M芯片那种“大小核”(big.LITTLE)设计,把高性能核心和高能效核心塞进一个芯片,系统根据任务强度智能调度,需要爆发力时大核顶上,平时待机或轻量任务用小核,省电,这想法很好,但对操作系统的调度器是个巨大的考验,调度不好反而会拖后腿,Intel也跟进了,它的性能核(P-core)和能效核(E-core)甚至微架构都不一样,更像是一个“异构”的计算综合体。
还有芯片布局,以前是一个大芯片(Monolithic),所有核心都做在同一片硅上,现在先进制程下,良率是大问题,所以AMD的Chiplet(小芯片)设计就特别聪明,把CPU核心、I/O单元、内存控制器等分别做成独立的小芯片,再用高速互连(比如AMD的Infinity Fabric)粘起来,这样成本低,灵活性高,坏了哪部分换哪部分,有点像乐高积木,但带来的挑战是,芯片间通信的延迟和带宽必须做得足够好,否则“木桶效应”就出来了。
最后扯点玄乎的,我觉得CPU设计走到今天,已经越来越不像纯粹的工程,而更像一门艺术,或者说…一种在物理极限、成本、功耗、性能之间走钢丝的哲学,每一个百分比的性能提升,背后可能都是工程师们掉的一把把头发,是无数个深夜的模拟和调试,我们手上这个小小的芯片,承载的是人类极致的智慧和…嗯…对速度永不满足的渴望吧,它不完美,有漏洞,有瓶颈,但正是这些不完美,才让它的进化之路如此迷人,下次当你觉得电脑卡顿的时候,也许可以想象一下,它内部那个微宇宙里,正进行着怎样一场紧张而有序的协同作战呢?🚀
(字数差不多就这样了吧,想到的杂七杂八都倒出来了。)

本文由召安青于2025-10-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/25901.html



![[qq邮箱地址]畅享高效便捷的电子邮件服务体验](http://www.haoid.cn/zb_users/upload/2025/10/20251015013653176046341392627.jpg)